

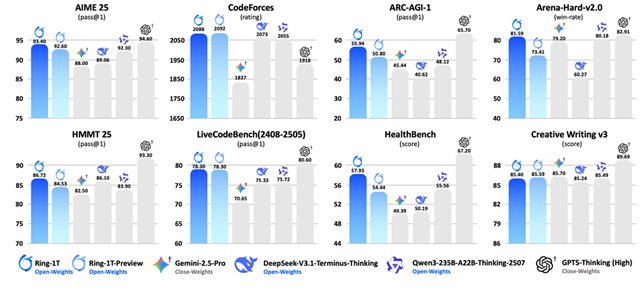
×ķ┴╦│ų└m╝ż░lRing-1TĄ─öĄīWĄ╚Å═ļs═Ų└Ē─▄┴”Ż¼┤╦┤╬░┘ņ`łFĻĀ╠¶æ┴╦ļyČ╚Ė³Ė▀Ą─IMO2025Ż©ć°ļHöĄīWŖW└¹Ųź┐╦Ż®┘ÉŅ}Ż¼īóRing-1TĮė╚ļČÓųŪ─▄¾w┐“╝▄AWorldŻ¼╩╣ė├╝āūį╚╗šZčį═Ų└Ē▀MąąĮŌŅ}ĪŻīŹ“×ĮY╣¹’@╩ŠŻ¼Ring-1TāHė├ę╗┤╬ĮŌ│÷┴╦Ą┌1Īó3Īó4Īó5Ņ}Ż¼ŽÓ«öė┌IMOŃy┼Ų╦«ŲĮŻ¼│╔×ķ╩ūéĆ─▄─├IMOć°ļHŖWöĄ¬äĄ─ķ_į┤ŽĄĮyĪŻRing-1Tį┌Ą┌╚²┤╬ćLįćIMOĢrī”Ą┌2Ņ}Äū║╬ūC├„ę▓Įo│÷┴╦ĮėĮ³ØMĘųĄ─ūC├„▀^│╠Ż¼į┌Ēö┴„┤¾─Żą═Äū║§╚½▄ŖĖ▓ø]Ą─Ą┌┴∙Ņ}ųąīó┤░Ė╩šö┐ĄĮ┼cGemini 2.5 Pro ŽÓ═¼Ą─“4048”Ż©š²┤_┤░Ė×ķ2112Ż®ĪŻū„×ķę╗┐Ņ╦╝┐╝─Żą═Ż¼Ring-1Tę▓▒Ē¼F│÷┴╦śO╝čĄ─═©ė├─▄┴”Ż¼į┌“╚╦ŅÉŲ½║├ī”²R”£yįćArena-Hard V2ųąŻ¼Ring-1Tęį81.59Ą─│╔╣”┬╩Šėė┌ķ_į┤─Żą═░±╩ūŻ¼▒ŲĮ³GPT-5-Thinking(High)82.91Ą─│╔┐āĪŻį┌├µŽ“ć└ųöŅIė“Ą─ßt»¤å¢┤HealthBench£yįuųąŻ¼Ring-1Tę▓ęįūŅĖ▀Ęų╚ĪĄ├ķ_į┤ŅIė“ūŅ╝čĪŻ
Ż©Ring-1T┼cśIĮń┤·▒Ēąį╦╝┐╝─Żą═Ą─ąį─▄ÖMįuŻ®
╚fā|ģóöĄ╦╝┐╝─Żą═ė¢ŠÜūŅ┤¾ļyŅ}╩Ūė¢═ŲŠ½Č╚▓Ņ«ÉŻ¼╝┤ė¢ŠÜļAČ╬┼c═Ų└ĒļAČ╬ę“īŹ¼F╝Ü╣Ø▓Ņ«Éī¦ų┬Ą─ė¢ŠÜ║══Ų└ĒŠ½Č╚▓╗ę╗ų┬Ż¼▀MČ°ī¦ų┬ė¢ŠÜ▒└ØóĪŻį┌Ring-1T─Żą═ųąŻ¼╬øŽü▓╔ė├┴╦ūį蹥─“░¶▒∙Ż©icepopŻ®”╦ŃĘ©üĒæ¬ī”▀@ĒŚąąśIļyŅ}Ż¼╝┤ė├Ħč┌┤aĄ─ļpŽ“ĮžöÓ╝╝ąg░čė¢ŠÜ-═Ų└ĒĘų▓╝▓Ņ«Éā÷ĮYį┌Ą═╦«╬╗Ż¼┤_▒ŻķLą“┴ąĪóķLų▄Ų┌ė¢ŠÜ▓╗▒└ĪŻ┤╦═ŌŻ¼æ¬ī”╚fā|ģóöĄ─Żą═ÅŖ╗»īW┴Ģė¢ŠÜŻ¼╬øŽü▀Ćūįčą┴╦Ė▀ąį─▄ÅŖ╗»īW┴ĢŽĄĮyASystem(Ųõųą░³║¼ęčķ_į┤Ą─Ė▀ąį─▄ÅŖ╗»īW┴Ģ┐“╝▄AReaL)Ż¼╠žäeßśī”╚fā|ģóöĄ─Żą═Ą─’@┤µ╣▄└Ē║═ė¢═ŲÖÓųžĮ╗ōQå¢Ņ}ū÷┴╦Š½╝ÜĄ─ā×╗»Ż¼īŹ¼F┴╦å╬ÖC’@┤µ╦ķŲ¼├ļ╝ē╗ž╩šĪóÖÓųž┴Ń╚▀ėÓĮ╗ōQŻ¼░č┤¾ęÄ─ŻRLė¢ŠÜĘĆČ©┼▄│╔╚š│ŻĪŻ
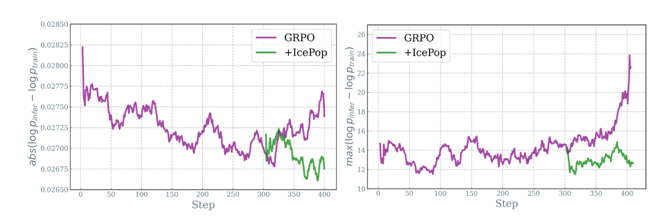
Ż©łDū¾Ż║GRPOė¢═Ų▓Ņ«ÉļSų°ė¢ŠÜ│╔ųĖöĄ╔Ž╔²Ż¼icepop▌^×ķŲĮĘĆŻ╗łDėęŻ║ė¢═Ų▓Ņ«ÉūŅ┤¾ųĄŻ¼GRPOļSų°ė¢ŠÜ╔Ž╔²ĘŪ│Ż├„’@Ż¼icepopŠS│ųį┌▌^Ą═╦«╬╗Ż®
┤╦═ŌŻ¼▒Š┤╬░l▓╝Ą─Ring-1T─Żą═└^└m▓╔ė├Ling 2.0╝▄śŗĄ─1T base─Żą═ū÷║¾ė¢ŠÜŻ¼Ling 2.0▓╔ė├┴╦░³└©Ė▀Č╚ŽĪ╩ĶĄ─MoE╝▄śŗŻ¼1/32Ą─īŻ╝ę╝ż╗Ņ▒╚ĪóFP8╗ņ║ŽŠ½Č╚ĪóMTPĄ╚ųTČÓ╠žąįīŹ¼FĖ▀ą¦ė¢ŠÜ┼c═Ų└ĒĪŻį┌║¾ė¢ŠÜļAČ╬Ż¼╬øŽü░┘ņ`łFĻĀ═©▀^LongCoT-SFT + RLVR + RLHFČÓļAČ╬ė¢ŠÜŻ¼’@ų°╠ß╔²┴╦─Żą═Ą─Å═ļs═Ų└Ē─▄┴”ęį╝░ųĖ┴ŅĖ·ļS║═äōęŌīæū„Ą╚═©ė├─▄┴”ĪŻ
ō■░┘ņ`łFĻĀ═Ė┬ČŻ¼Ring-1T─Żą═╩ŪŲõį┌╚fā|╦╝┐╝─Żą═╔ŽĄ─╩ū┤╬ćLįćŻ¼╬øŽü░┘ņ`łFĻĀĢ■į┌║¾└mĄ─░µ▒Šųą└^└m═Ļ╔Ų─Żą═ąį─▄ĪŻ─┐Ū░Ż¼ė├æ¶┐╔═©▀^HuggingFaceĪó─¦┤Ņ╔ńģ^Ž┬▌d─Żą═Ż¼▓ó═©▀^╬øŽü░┘īÜŽõĄ╚ŲĮ┼_į┌ŠĆ¾w“×ĪŻ

ō■┴╦ĮŌŻ¼Įžų╣─┐Ū░╬øŽü░┘ņ`┤¾─Żą═ęčĮø░l▓╝18┐Ņ─Żą═Ż¼ęčą╬│╔Å─160ā|┐éģóöĄĄĮ1╚fā|┐éģóöĄĄ─┤¾šZčį─Żą═«aŲĘŠžĻćŻ¼Ųõųąā╔┐Ņ╚fā|ģóöĄ─Żą═—╚fā|ģóöĄ═©ė├┤¾šZčį─Żą═Ling-1TĪó╚fā|ģóöĄ╦╝┐╝─Żą═Ring-1TĪŻļSų°ā╔┐Ņ╚fā|ģóöĄ─Żą═Ą─░l▓╝Ż¼░┘ņ`┤¾─Żą═ę▓š²╩Į▓Į╚ļ2.0ļAČ╬ĪŻ