


═Ż▄ćł÷│÷╚ļ┐┌ūR(sh©¬)äeŲ┐Ņi
╔Ž╩÷═┤³c(di©Żn)ę╗ätįņ│╔┴╦ė├涾w“×(y©żn)╩╝ĮK▓╗Ė▀Ż¼Č■ät¤oĘ©×ķ¤o╚╦ųĄ╩ž╠ß╣®▒žąĶĄ─╗∙ĄA(ch©│)Ż©▄ć┼ŲūR(sh©¬)äe┬╩▒žĒÜĮėĮ³100%Ż®ĪŻ
“╗č█šķŠ” - ▓üŽĄ┴ą▄ć┼ŲūR(sh©¬)äeę╗¾wÖC(j©®)”Ż©ęįŽ┬║åĘQ“▓ü”Ż®Ą─═Ų│÷ätÅžĄū═╗ŲŲ┴╦╔Ž╩÷Ų┐ŅiŻ║

“▓ü”═╗ŲŲ═Ż▄ćł÷│÷╚ļ┐┌Ų┐Ņi
─Ū├┤“▓ü”╩Ū╚ń║╬īŹ(sh©¬)¼F(xi©żn)╔Ž╩÷═╗ŲŲĄ──žŻ┐Ęų×ķā╔³c(di©Żn)Ż║
ę╗╩Ū╗∙ė┌ļp─┐┴ó¾węĢėXŻ¼ī”ł÷Š░╔ŅČ╚ą┼ŽóĄ─═┌Š“Ż╗Č■╩Ū½@╚Ī╔ŅČ╚ą┼Žó║¾Ż¼ī”▄ć▌v▀M(j©¼n)ąąīŹ(sh©¬)Ģr(sh©¬)3DĮ©─ŻĪŻ
“▓ü”Ž╚╩Ū╗∙ė┌ļp─┐┴ó¾węĢėXŻ¼ī”ł÷Š░╔ŅČ╚ą┼Žó▀M(j©¼n)ąą═┌Š“ĪŻ
─Ū├┤╩▓├┤╩Ū“ł÷Š░╔ŅČ╚ą┼Žó”Ż┐║åå╬šfüĒŻ¼Š═╩Ū╚²ŠS┴ó¾wū°ś╦(bi©Īo)ųąŻ¼z▌S╔Ž│ą▌dĄ─ą┼ŽóŻ║

łD1 ╚²ŠS┴ó¾wū°ś╦(bi©Īo)
╚ńłD1Ż¼ł÷Š░ųąxĪóy▌Sśŗ(g©░u)│╔Č■ŠSŲĮ├µą┼ŽóŻ¼z▌S┤Ņ▌dĄ─▒Ń╩Ūł÷Š░╔ŅČ╚ą┼ŽóĪŻ

łD2 Č■ŠSŲĮ├µą┼Žó▓╔╝»
╚ńłD2Ż¼å╬─┐ŽÓÖC(j©®)ų╗─▄▓╔╝»Č■ŠSŲĮ├µą┼ŽóŻ¼╝┤XĪóY▌S╔ŽĄ─ą┼ŽóĪŻ

łD3 ╚²ŠS┴ó¾wą┼ŽóĮŌ╬÷
╚ńłD3Ż¼ĮĶų·ļp─┐┴ó¾węĢėXī”ł÷Š░╔ŅČ╚ą┼ŽóĄ─═┌Š“Ż¼“▓ü”īŹ(sh©¬)¼F(xi©żn)┴╦ī”ł÷Š░╚²ŠS┴ó¾wą┼ŽóĄ─ĮŌ╬÷ĪŻ
½@╚Īł÷Š░╔ŅČ╚ą┼Žó║¾Ż¼“▓ü”īóĢ■(hu©¼)ī”ł÷Š░ųą▄ć▌v▀M(j©¼n)ąąīŹ(sh©¬)Ģr(sh©¬)3DĮ©─ŻĪŻ

łD4 ▄ć▌vīŹ(sh©¬)Ģr(sh©¬)3DĮ©─Ż
▄ć▌v3DīŹ(sh©¬)Ģr(sh©¬)Į©─ŻĄ──┐Ą─╩Ū▀ĆįŁ▄ć▌vĄ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)Ż©╚ń▄ć┼Ų│▀┤ńĪó▄ć▌vķLīÆĖ▀Īó┐šķgŠÓļxĄ╚Ż®ĪŻ
▄ć▌vīŹ(sh©¬)Ģr(sh©¬)3DĮ©─Żį┘ĮY(ji©”)║ŽĖ▀Š½Č╚ūR(sh©¬)äe╦ŃĘ©Ż¼╩╣Ą├“▓ü”īŹ(sh©¬)¼F(xi©żn)┴╦100%▄ć▌vęĢŅlė|░l(f©Ī)Īó▄ć┼ŲĘ└é╬Īó═Ļ╚½Č┼Į^š`ūR(sh©¬)äeĪŻ
╚ń╣¹šf╔Ž╬─“ł÷Š░╔ŅČ╚ą┼Žó═┌Š“”Īó“▄ć▌vīŹ(sh©¬)Ģr(sh©¬)3DĮ©─Ż”ųv╩÷Ą─╩Ū“▓ü”Ą─▄ø╝■įŁ└ĒŻ¼─Ū├┤“▓ü”Ą─ė▓╝■ų¦│ų╗∙ĄA(ch©│)Š═╩Ū“╠žųŲ╗»«Éśŗ(g©░u)ļpńRŅ^”ĪŻ
īŹ(sh©¬)ļH╔ŽŻ¼ļpńRŅ^įO(sh©©)ėŗ(j©¼)įńŠ═ÅVĘ║æ¬(y©®ng)ė├ė┌é„Įy(t©»ng)░▓Ę└ąąśI(y©©)ųąŻ¼Ųõ«a(ch©Żn)ŲĘą╬æB(t©żi)ų„ę¬Ęų×ķ╚²ĘNŻ║
1ĪóŲš═©ńRŅ^┼c╝t═ŌńRŅ^Ą─ĮM║ŽŻ¼ė├ė┌Ģāę╣▒O(ji©Īn)┐ž
2Īó╗∙ė┌ķLČ╠Ųž╣ŌĢr(sh©¬)ķg▓╗═¼Ż¼śŗ(g©░u)Į©īÆäė(d©░ng)æB(t©żi)ąį─▄
3Īó▀xō±ā╔éĆ(g©©)▓╗═¼Į╣ŠÓĄ─ńRŅ^Ż¼│╩¼F(xi©żn)▓╗═¼Į╣ŠÓŽ┬Ą─│╔Ž±ą¦╣¹

łD5 ╠žųŲ╗»«Éśŗ(g©░u)ļpńRŅ^śŗ(g©░u)Į©┴ó¾węĢėX
╚ńłD5╦∙╩ŠŻ¼“▓ü”ģs▓╗╩Ūā╔éĆ(g©©)özŽ±Ņ^Ą─║åå╬»B╝ėŻ¼╦³▓╔ė├╠žųŲ╗»«Éśŗ(g©░u)ļpńRŅ^Ą─ūŅĮK─┐Ą─Ż¼╩Ū×ķ┴╦│ų└m(x©┤)ĘĆ(w©¦n)Č©Ąžśŗ(g©░u)Į©ļp─┐┴ó¾węĢėXĪŻ
═©▀^Ū░├µĄ─ĮķĮBŻ¼Žļ▒ž┤¾╝ę┤¾ų┬┴╦ĮŌ┴╦“▓ü”╚ń║╬═╗ŲŲ═Ż▄ćł÷│÷╚ļ┐┌Ų┐ŅiĪŻĮėŽ┬üĒŻ¼╬ęéāīóĢ■(hu©¼)šf├„“▓ü”śŗ(g©░u)Į©┴ó¾węĢėXĄ─╗∙ĄA(ch©│)—ęĢ▓ŅįŁ└ĒĪŻ
╩▓├┤╩ŪęĢ▓ŅįŁ└ĒŻ┐╬ęéā┐╔ęįė├╚╦č█«a(ch©Żn)╔·┴ó¾węĢėXĄ─▀^│╠▀M(j©¼n)ąąĻUßīĪŻ

łD6 ū¾ėęč█½@╚Īā╔Ę∙▓╗═¼Ą─łDŽ±
╚ńłD6Ż¼╚╦Ą─ļpč█ŽÓŠÓę╗Č©Ą─═½ŠÓŻ¼ę“┤╦ū¾ėęč█╩ŪÅ─┬į╬ó▓╗═¼Ą─ĮŪČ╚ė^▓ņ╬’¾wŻ¼½@╚Ī═¼ę╗╬’¾wĄ─ā╔Ę∙▓╗═¼łDŽ±ĪŻ
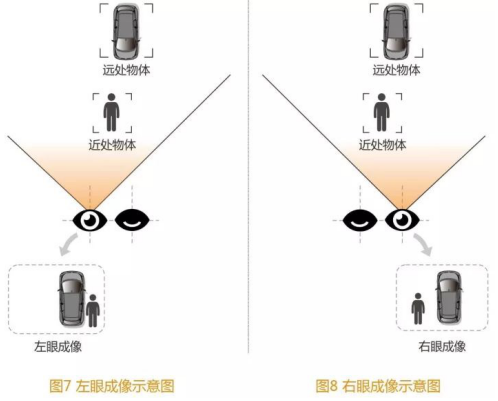
╚ńłD7╦∙╩ŠŻ¼Į³╠Äėąę╗éĆ(g©©)╚╦Ż¼▀h(yu©Żn)╠Äėą▌v▄ćŻ¼ī”ė┌ū¾č█ą╬│╔Ą─łDŽ±Ż¼╚╦Ģ■(hu©¼)į┌▄ćĄ─ėęé╚(c©©)ĪŻ
╚ńłD8╦∙╩ŠŻ¼Č°ėęč█ą╬│╔Ą─łDŽ±ųąŻ¼╚╦Ģ■(hu©¼)į┌▄ćĄ─ū¾é╚(c©©)ĪŻ

╚ńłD9Ż¼ī”æ¬(y©®ng)═¼ę╗ł÷Š░Ż¼ļpč█╔·│╔▓╗═¼Ą─łDŽ±ĪŻ
╚ńłD10Ż¼ū¾č█│╔Ž±ųąĄ─╚╦┼cėęč█│╔Ž±ųąĄ─╚╦Ż¼ā╔š▀ķgĄ─ęĢ▓ŅŽÓī”Ė³┤¾ĪŻū¾č█│╔Ž±ųąĄ─▄ć┼cėęč█│╔Ž±ųąĄ─▄ćŻ¼ā╔š▀ķgĄ─ęĢ▓ŅŽÓī”Ė³ąĪĪŻļpč█š²╩Ūę└ō■(j©┤)ęĢ▓ŅĄ─▓╗═¼Ż¼Ėąų¬ł÷Š░╔ŅČ╚ą┼ŽóŻ¼▀@Š═╩ŪęĢ▓ŅįŁ└ĒĪŻ
ŠC╔Ž╦∙╩÷Ż¼“▓ü”Ą─═Ų│÷Ż¼═╗ŲŲ┴╦═Ż▄ćł÷│÷╚ļ┐┌ūR(sh©¬)äeĄ─╣╠ėąŲ┐ŅiŻ¼śO┤¾ĄžĖ─╔Ų┴╦ė├æ¶ār(ji©ż)ųĄ║═¾w“×(y©żn)Ż¼ė╚Ųõ╩Ū×ķ¤o╚╦╗»ųĄ╩žĄ─īŹ(sh©¬)╩®ĄņČ©║╦ą─╗∙ĄA(ch©│)ĪŻ
¤o╚╦╗»ųĄ╩ž▓╗āH─▄ūīŽĄĮy(t©»ng)╝»│╔╔╠Ą─ŠSūo(h©┤)│╔▒Š┌ģĮ³ė┌┴ŃŻ¼Ė³×ķ═Ż▄ćł÷╣▄└ĒĘĮ├Ō╚ź╚╦┴”│╔▒ŠŻ¼╩Ū═Ż▄ćł÷│÷╚ļ┐┌ūR(sh©¬)äe▒ž╚╗Ą─░l(f©Ī)š╣┌ģä▌ĪŻ