

2016ųąć°æ¬ė├ąį─▄╣▄└Ē┤¾Ģ■▀\ŠSūįäė╗»īŻł÷58ĄĮ╝ę╝▄śŗĤ╚╬╠ęągŅ}×ķĪČ58ĄĮ╝ęĘ■äšų╬└Ē║═Ė·█ÖŽĄĮy(t©»ng)ĪĘĄ─č▌ųvŻ¼¼Fł÷ĮŌūx┴╦Ģ■ųž³cųvĮŌ58ĄĮ╝ęį┌╠Ä└Ēī”ŽĄĮy(t©»ng)ąį─▄Ą─▒O(ji©Īn)┐žĪó┴„┴┐▒O(ji©Īn)┐žĪó┐ņ╦┘öU╚▌Ą╚ļy³c╔ŽĄ─ĮŌøQĘĮ░Ė║═▒O(ji©Īn)┐žŽĄĮy(t©»ng)Ą─įOėŗ╦╝┬ĘĪŻ
┤¾╝ęŽ┬╬ń║├Ż¼╬ęĮą╚╬╠ęągŻ¼üĒūį58ĄĮ╝ęĪŻĮ±╠ņĮo┤¾╝ęĘųŽĒĄ─ų„ę¬ā╚╚▌╩ŪĪČ58ĄĮ╝ęĘ■äšų╬└ĒīŹ█`ĪĘĪŻ
╬ęéāÅ─╚²éĆĘĮ├µüĒ▀MąąŻ¼Ą┌ę╗éĆ╩Ū×ķ╩▓├┤ąĶę¬Ę■äšų╬└ĒŻ¼Ą┌Č■éĆ╩Ū58ĄĮ╝ę╩Ūį§śėį┌Ę■äšų╬└Ē▀@ę╗ēKīŹ█`ū÷┴╦──ą®╩┬ŪķŻ¼ūīŽĄĮy(t©»ng)─▄ē“Ė³║├Ą─▀\ąą;ūŅ║¾╩ŪąĪĮYĪŻ
×ķ╩▓├┤ąĶę¬Ę■äšų╬└Ē?
įńŲ┌58ĄĮ╝ęę▓╩Ūę╗éĆ│§äō(chu©żng)ą═Ą─╣½╦ŠŻ¼░³└©╝ęš■Īó¹É╚╦Īó╦┘▀\Īó╚²ĘĮŲĮ┼_Ż¼įńŲ┌ę“×ķ╩Ū│§äō(chu©żng)╣½╦Š┤¾╝ęČ╝├”ė┌ØMūŃąĶŪ¾Ą─čą░l(f©Ī)Ż¼║▄╔┘ī”ę╗ą®╣½╣▓Ę■äš╗“š▀╣½╣▓ĮM╝■▀MąąĘųčbĪŻ
─ŪĢr║“╬ęéāėą▓╗═¼Ą─čą░l(f©Ī)łFĻĀį┌ŠSūoų°▓╗═¼Ą─śI(y©©)䚯¼╦∙ęįšf│÷¼F┴╦║▄ČÓŅÉ╦ŲĄ─ųžÅ═ŽĄĮy(t©»ng)Ż¼▒╚╚ńšf╩šŃy┼_Ż¼╗“š▀ėåå╬Īóų¦ĖČŽĄĮy(t©»ng)Ą╚Ą╚ĪŻ▀@śėĢ■ī¦ų┬╩▓├┤å¢Ņ}?┤·┤aųžÅ═┬╩Ė▀Ż¼┐╔ŠSūoąįĘŪ│Ż▓ŅĪŻ┴Ē═Ō╬ęéāį┌ū÷ę╗ą®£yįć╗“š▀ķ_░l(f©Ī)Ż¼░³└©ę╗ą®Ą³┤·Ė³ą┬Ą─Ģr║“Ż¼╚ń╣¹ø]ėąę╗ą®╣½╣▓Ę■䚯¼į┌├┐éĆ▓╗═¼śI(y©©)䚊Ćų╗ę¬ėąę╗▓┐Ęų╣”─▄ą▐Ė─Ż¼╦∙ėąĄ─śI(y©©)ŠĆČ╝Č╝ę¬ū÷š{š¹Ż¼¤oĘ©ū÷ĄĮ├¶Į▌Į╗ĖČĪŻ
┴Ē═Ōį┌öĄō■▀@ę╗ēKŻ¼╬ęéāįńŲ┌ę▓╩Ūį§├┤┐ņį§├┤ū÷ĪŻ║▄ČÓśI(y©©)䚎ĄĮy(t©»ng)Ą─öĄō■Ż¼ų«Ū░╩Ūį┌ę╗éĆ┤¾Äņ└’├µ┤¾Ė┼ėą║├Äū░┘Åł▒ĒŻ¼║¾└m(x©┤)Ė∙ō■śI(y©©)䚥─╠žš„Ż¼ŽĄĮy(t©»ng)Ą─┬Üž¤ū÷┴╦ę╗ą®ĮŌ±ŅĪŻ│§äō(chu©żng)ąį╣½╦Š▀Ć╩ŪęįąĶŪ¾Ēææ¬┐ņ×ķ─┐ś╦Ż¼Ą½╩Ū¼Fėą╝▄śŗ▓╗─▄ØMūŃ58ĄĮ╝ęčĖ├═Ą─śI(y©©)äš░l(f©Ī)š╣ąĶŪ¾Ż¼╦∙ęį╬ęéāėą┴╦║¾└m(x©┤)ę╗ŽĄ┴ąĄ─äėū„ĪŻ
Ę■äš╗»+┴ó¾w╗»▒O(ji©Īn)┐ž
ū÷Ą─Š═╩ŪĘ■äš╗»+┴ó¾w╗»▒O(ji©Īn)┐žĪŻ╩ūŽ╚ę¬ū÷Ą─ę╗╝■╩┬ŪķŠ═╩ŪĘ■äš▓ĘųŻ¼╬ęéāĖ∙ō■śI(y©©)䚥─╠žš„ęį╝░ŽĄĮy(t©»ng)Ą─┬Üž¤ū÷┴╦ę╗ą®┤╣ų▒äØĘųŻ¼═¼ĢrĖ∙ō■śI(y©©)äšų«ķgĄ─Į╗╗ź╠Ä└ĒŻ¼═©▀^Ž¹ŽóĄ─ĘĮ╩ĮīŹ¼F┴╦ĮŌ±Ņū÷┴╦╦«ŲĮ▓ĘųĪŻ═©▀^Ę■äš╗»╬ęéā┐╔ęįū÷ĄĮ░čų«Ū░ę╗ą®╣żū„Ą──ŻēKĮŌ±ŅŻ¼ū÷ĄĮĘ■äš┐ņ╦┘öU╚▌ĪŻ╬ęéā═Ļ│╔¼Fėą▒O(ji©Īn)┐ž┐╔ęįū÷ĄĮ▒╚▌^╝░Ģr░l(f©Ī)¼Få¢Ņ}Ż¼▓╗ų┴ė┌║▄▒╗äėĄ─Ēææ¬┐═Ę■Ą─═ČįVĪŻ
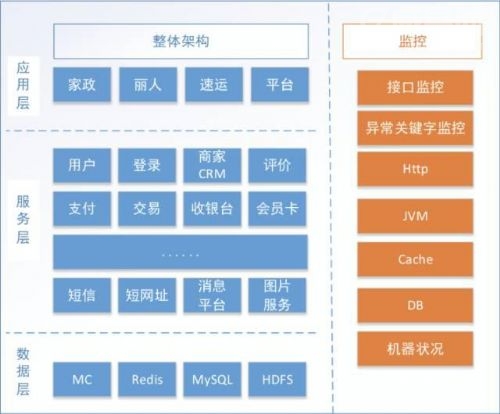
ļm╚╗ū÷┴╦╝▄śŗ╔²╝ēŻ¼Ą½╩Ū▀Ć╩Ū├µ┼R┴Ē═Ōę╗éĆå¢Ņ}Ż║╬ęéāĘ■äš╗»═¼ĢrŽĄĮy(t©»ng)ęÄ(gu©®)─ŻįĮüĒįĮ┤¾Ż¼š¹¾w╝▄śŗįĮüĒįĮÅ═ļsŻ¼Ę■äšę▓įĮüĒįĮČÓŻ¼Ę■äšų«ķgš{ė├Ą─ĻPŽĄę▓įĮüĒįĮÅ═ļsŻ¼ī¦ų┬į┌┼┼▓ķ─│ę╗éĆå¢Ņ}Ģr║▄┐╔─▄│÷¼Fš¹éĆš{ė├µ£╠½ķLŻ¼į┌┼┼▓ķå¢Ņ}Ą─Ģr║“¤oĘ©║▄┐ņĄ─Č©╬╗å¢Ņ}Š▀¾w░l(f©Ī)╔·į┌──ę╗īėŻ¼╦∙ęį╬ęéāėųū÷┴╦║¾└m(x©┤)Ą─ę╗ą®äėū„ĪŻ
ĄĮ╝ęĘ■äšų╬└ĒīŹ█`
Į±╠ņų„ę¬ųvę╗Ž┬58ĄĮ╝ęßśī”Ę■äšų╬└Ēķ_š╣Ą─╩┬ŪķĪŻų„ę¬░³└©ŠG┐“└’├µĄ─Äū▓┐Ęųā╚╚▌Ż¼║¾└m(x©┤)ųž³cųvę╗Ž┬58ĄĮ╝ę╩Ūį§śėį┌Ę■äš╗»ų╬└ĒĄ─┬Ę╔ŽŻ¼ū÷┴╦──ą®╩┬ŪķĪŻ

╚ń╣¹ū÷Ę■äš╗»┐ŽČ©ę¬░čĘ■䚥─ĄžųĘ▒®┬Č│÷üĒŻ¼╬ęéāĢ■ėąę╗éĆūóāįųąą─Ż¼▀@éĆųąą─Ą─īŹ¼FėąČÓĘNĪŻ┤¾ų┬Ą─ū÷Ę©╩ŪĢ■░čūóāįųąą─Ė·Ę■äš╠ß╣®š▀║═Ę■䚎¹┘Mš▀┬ōŽĄŲüĒŻ¼╬ęéāĢ■ėąę╗éĆķLµ£ĮėĄ─▒Ż│ųŻ¼«ö×ķĘ■äšĘĮåóäėĄ─Ģr║“Ż¼Š═┐╔ęį░čĘ■äš╠ß╣®š▀Ą─ą┼ŽóŻ¼░³└©Ę■䚥─├¹ĘQŻ¼╗“š▀Ę■䚥─Č╦┐┌╔Žł¾ĄĮūóāįųąą─ĪŻī”ė┌Ž¹┘Mš▀üĒšfŻ¼╦¹éāĢ■Ė∙ō■śI(y©©)䚥─ąĶ꬯¼īó▀@ą®Ę■äššµš²░l(f©Ī)Ų▀h│╠š{ė├ĢrÅ─ūóāįųąą─½@╚ĪŽÓ欎¹┘Mš▀Ą─ą┼ŽóĪŻ╬ęéāū÷Ę■äšöU╚▌Ż¼ī”ė┌┐═æ¶ĘĮüĒšfī”Ę■䚥žųĘ╩Ū¤oĖąų¬Ą─ĪŻįńŲ┌│§äō(chu©żng)ąį╣½╦Šį┌Ę■äšöU╚▌Ą─Ģr║“Ż¼╩ŪąĶę¬Ė³Ė─Ę■䚥─ę╗ą®┼õų├╣Ø(ji©”)³cŻ¼ąĶ꬚¹¾wĘ■äš▓┼─▄▀_ĄĮ▀@śėĄ─ą¦╣¹ĪŻ
┴Ē═ŌŠ═╩Ū╗∙ė┌ūóāįųąą─Ż¼╬ęéā┐╔ęįū÷Ę■䚥─ĘųĮMęį╝░░▓╚½Ą─£y┴┐ĪŻ▒╚╚ńšf▓╗═¼Ą─śI(y©©)äšĘĮĢ■ėą▓╗═¼Ą─ąĶŪ¾ā×(y©Łu)Ž╚╝ē╗“š▀šfŽĄĮy(t©»ng)Ą─ųžę¬ąįŻ¼╬ęéāĢ■Ė∙ō■▓╗═¼Ą─śI(y©©)äšĘĮĮo╦³▀Mąą▓╗═¼Ą─Ę■äšĘųĮMŻ¼▀@śė┐╔ęįū÷ĄĮĘ■䚥─Ė¶ļxĪŻ
┴Ē═Ō▀Ćėąę╗ą®╣żū„ę▓╩Ū═©▀^ūóāįųąą─ū÷Ą─Ż¼╬ęéā┐╔ęįū÷ę╗ą®TCPą─╠°▒O(ji©Īn)£yŻ¼▒ŻūCĘ■䚥─┐╔ė├ąįĪŻ
Ė▀┐╔ė├▀@ĘĮ├µŻ¼ę“×ķūóāįųąą─╩Ūę╗éĆÅŖę└┘ćĄ─¢|╬„Ż¼▓╗╣▄╩ŪĘ■äš╠ß╣®š▀▀Ć╩ŪĘ■䚥─Ž¹┘Mš▀Ż¼Č╝╩ŪÅŖę└┘ćĄ─ĮM╝■Ż¼╦∙ęįūóāįųąą─Ą─ųžę¬ąįŠ═▓╗čįČ°ė„┴╦Ż¼▒žĒÜę¬▒ŻūCūóāįųąą─Ą─Ė▀┐╔┐┐ąįĪŻ═©▀^ā╔éĆĘĮ├µŻ¼ę╗ĘĮ├µŠ═╩Ū▒Š╔Ēūóāįųąą─╩Ūėąā”éõĄ─ĪŻ┴Ē═Ōį┌Ž¹┘Mš▀▀@▀ģŻ¼«ö═┌╚ĪĄĮ┴╦ūóāįųąą─Ę■äš╠ß╣®ĘĮĄ─┼õų├ą┼Žóų«║¾Ż¼┐╔ęįį┌▒ŠĄžū÷ę╗éĆéõĘ▌Ż¼▀@śėŠ═┐╔ęį▓╗į┘─Ū├┤ÅŖę└┘ćė┌ūóāįųąą─┴╦Ż¼▀@╩ŪĘ■䚥─░l(f©Ī)▓╝║═ėåķåĪŻ

┴Ē═Ōßśī”ę╗éĆĘ■äš╝»╚║Ż¼ąĶę¬ū÷ŽÓæ¬Ą─Ę■äš╝»╚║┬Ęė╔║═╚▌ÕeĪŻ
Ę■äš╝»╚║┬Ęė╔&╚▌Õe
┬Ęė╔Ą─ĘĮ╩ĮŻ¼╬ęéā¼Fį┌Ą─╩ŪļSÖCĪó▌åõŁĪó╗∙ė┌ÖÓųžĪó╗∙ė┌žō▌dĄ─Ż¼¤oĘ©Ė∙ō■¼FėąĘ■äšŲ„┼õų├ū÷žō▌dĄ─Ęų░l(f©Ī)ĪŻ╗∙ė┌ÖÓųžę▓╩Ū│§╩╝╗»Ą─Ģr║“Ż¼ėąę╗éĆņoæB(t©żi)Ą─Ęų┼õĪŻžō▌d▒╚╚ńšf┐═æ¶Č╦Ė∙ō■Ę■äšŲ„ĘĄ╗žĄ─Ēææ¬ĢrķgŻ¼øQČ©║¾└m(x©┤)šłŪ¾Ą─Ęų░l(f©Ī)ĪŻ
Ųõ┤╬Ż¼╬ęéāėąę╗ŽĄ┴ąĄ─┬Ęė╔▓▀┬į¼Fį┌ę▓╩Ū┼õų├╗»Ą─Ż¼┐╔ęįĖ∙ō■IPĄžųĘČ╬ū÷┬Ęė╔Ż¼═¼Ģr┐╔ęįĖ∙ō■ĘĮĘ©├¹ĘQŻ¼▒╚╚ńšfę¬ū÷ūxīæĘųļxŻ¼┐╔ęįĖ∙ō■ĘĮĘ©▓ķįāĄ─Ż¼▀Ć╩ŪšfĖ³ą┬Ą─╗“╩Ūą┬į÷Ą─Ż¼┐╔ęįū÷▓╗═¼Ą─ĘĮĘ©├¹Ųź┼õŻ¼į┘ū÷ŽÓæ¬┬Ęė╔ĪŻĘ■äšĘųĮMŻ¼╬ęéā┐╔ęįĖ∙ō■īŹļHśI(y©©)䚥─ł÷Š░Ż¼śI(y©©)䚥─ųžę¬ąįŻ¼ī”Ę■äš▀MąąĘųĮMŻ¼ū÷ŽÓæ¬Ą─Ė¶ļxĪŻ
┴Ē═Ō▀Ćėąę╗ą®╠ž╩ŌĄ─ąĶŪ¾Ż¼┐╔─▄Ģ■Ė∙ō■─│ę╗ą®śI(y©©)äš╠žš„Ż¼ąĶę¬░čĘ■äš┬Ęė╔ĄĮ╣╠Č©Ą──│ę╗Ę■äšŲ„╔ŽŻ¼Ė∙ō■╠ž╩ŌĄ─┬Ęė╔ęÄ(gu©®)ät╠ß╣®┬Ęė╔Ą─öUš╣Ż¼┐╔ęįĮośI(y©©)䚊Ćū÷ŽÓæ¬╠ž╩Ō╗»Ą─┬Ęė╔ĪŻ
╚▌ÕeĘĮ├µūŅų„ę¬ę╗³cŠ═╩Ū╣╩šŽ▐DęŲĪŻ¼Fį┌į┌ū÷Ę■äš╗»Ą─Ģr║“Ż¼╬ęéāČ╝╩Ūę¬Ū¾╩ŪāńĄ╚Ą─Ę■äšĪŻū÷╣╩šŽ▐DęŲĢr╚ń╣¹ę╗éĆĘ■äš▓╗╩ŪāńĄ╚Ą─Ż¼┐╔─▄Ģ■│÷¼F╬ęéā▒Š╔Ē▓╗Ų┌═¹Ą─ĮY╣¹ĪŻ
╩¦öĪŠÅ┤µę▓ėąŽÓæ¬Ą─ÖCųŲŻ¼╬ęéā┐╔ęįīó╩¦öĪĄ─ę╗ą®šłŪ¾Ż¼į┌▒ŠĄžū÷ę╗éĆčėĢrĄ─įLå¢Ż¼į┘▀^Č╬Ģrķgųžįć▀@éĆĘ■äš╩Ū▓╗╩Ū┐╔ęį┴╦ĪŻ╩¦öĪ═©ų¬┼c┐ņ╦┘╩¦öĪŻ¼ę▓╩Ū×ķ┴╦Ė³║├Ą─┐ņ╦┘ĘĄ╗žĪŻ
┬Ęė╔║═╚▌Õe▀@ę╗ēKŻ¼į┌īŹ█`▀^│╠ųąķgąĶę¬ūóęŌŻ¼╩ūŽ╚╬ęéā▒žĒÜ▒ŻūCĘ■äš╩Ū¤oĀŅæB(t©żi)ĪŻ╚ń╣¹šfšµę¬╩Ūėąę╗ą®Ė·ĀŅæB(t©żi)ŽÓĻPĄ─śI(y©©)䚯¼╬ęéāĮ©ūh╩Ū░č╦³Ę┼ĄĮöĄō■īėŻ¼╗“š▀═©▀^ŠÅ┤µĄ─ĘĮ╩Į░čĖ·ĀŅæB(t©żi)ėąĻPĄ─öĄō■┤µā”ĪŻ«öę╗éĆ╣Ø(ji©”)³c│÷å¢Ņ}Ą─Ģr║“Ż¼╬ęéāųžįO┐╔ė├Ą─Ųõ╦¹╣Ø(ji©”)³cĪŻ
į┌ųžįć▀^│╠ųąę¬ūóęŌę╗Ž┬Ģ■ėąę╗éĆčėĢrŻ¼╬ęéā▓╗┐╔─▄¤oŽ▐ųŲĄ─ū÷ųžįćĪŻę“×ķį┌┐═æ¶Č╦ę╗░Ń═∙═∙Ģ■įOų├ĢrķgŻ¼╚ń╣¹┐═æ¶Č╦ū÷┴╦╠½ČÓćLįćŻ¼ī”欚¹éĆśI(y©©)䚥─ĘĄ╗žęčĮøø]ėą▒žę¬ųžįć┴╦Ż¼ę“×ķśI(y©©)äšĘĮ─Ū▀ģęčĮø│÷å¢Ņ}┴╦ĪŻ▀@╩Ūį┌┬Ęė╔║═╚▌Õe▀@ę╗ēKŻ¼╬ęéāū÷Ą─ę╗ą®╩┬ŪķĪŻ
┴„┴┐┐žųŲ&┴„┴┐ĖµŠ»
×ķ┴╦ī”Ę■äšū÷ę╗ą®▀^▌dĄ─▒ŻūoŻ¼╬ęéāū÷┴╦┴„┐ž║═┴„┴┐Ą─ĖµŠ»ĪŻ┴„┐žŠ═╩Ūę¬▒Ż├³Ż¼«ö╬ęĄ─šłŪ¾▓╗╣▄╩Ūę“×ķ╗Ņäė│÷┤¾ÕeŻ¼▀Ć╩Ūę╗ą®š`▓┘ū„╗“š▀ĘŪĘ©š{ė├ī¦ų┬š¹éĆöĄō■šłŪ¾═╗╚╗╔ŽüĒų«║¾Ż¼ę¬ū÷║├ŽÓæ¬╣żū„ĪŻ╩ūŽ╚Ģ■įOų├ę╗éĆ┴„┐žĄ─ķōųĄŻ¼«öįLå¢┴┐▀_ĄĮķōųĄ80%Ą─Ģr║“Ģ■ėą╠ßŪ░ĖµŠ»Ż¼▓╗ų┴ė┌║▄▒╗äėĄ─╚źĮŌøQå¢Ņ}Ż¼╗“š▀šfø]ėąŽÓæ¬ūŃē“Ą─Ģrķgūī╬ęéā╚ź£╩éõ╠Ä└Ēå¢Ņ}ĪŻ
«öšµš²░l(f©Ī)╔·┴„┴┐Ė▀ĘÕĄ─Ģr║“Ż¼╬ęéāę¬ū÷Ą─╩┬Ūķ└ĒŽļĄ─╩ŪūįäėöU╚▌Ż¼¼Fį┌╩Ū═©▀^╩ųäėĄ─┐ņ╦┘öU╚▌üĒū÷Ą─ĪŻ╩ųäė┐ņ╦┘öU╚▌▒žĒÜ▌oų·ūóāįųąą─Ż¼Ž¹┘Mš▀▀@▀ģī”Ę■䚥─ĄžųĘ╩Ū═Ė├„Ą─Ż¼┐═æ¶ĘĮ▓╗ė├ū÷╚╬║╬š{š¹Ż¼─▄ē“ūī┐═æ¶Č╦ū÷ĄĮ┐ņ╦┘öU│õĪŻ
ū÷┴„┐žķōųĄĄ─į┌ŠĆš{š¹Ż¼▀@éĆĢr║“┐╔ęįū÷ĄĮīŹĢr╔·ą¦Ą─ĪŻų«Ū░įOų├Ą─ķōųĄ┐╔─▄▓╗║Ž└ĒŻ¼╗“š▀ø]ėąĄĮ╠ž╩ŌśI(y©©)äšł÷Š░Ż¼╬ęéā┐╔ęįū÷ĄĮīŹĢrį┌ŠĆš{š¹ķōųĄĪŻ
┴„┴┐ĖµŠ»Ą─įÆŻ¼╬ęéāĢ■ėąĄ─ķōųĄŻ¼┴Ē═Ō▀Ćėą▓©Č╬Ą─ķōųĄŻ¼▀@ę╗ĘųńŖ║═╔Žę╗ĘųńŖ▒╚▌^┴„┴┐╩Ū▓╗╩Ūėą▒╚▌^┤¾Ą─▓©äėŻ¼╚ń╣¹ėą┤¾Ą─▓©äėŻ¼▓╗╣▄╩Ū┴„┴┐═╗╚╗╔Ž╔²▀Ć╩Ū═╗╚╗Ž┬ĮĄČ╝ėą┴„┴┐▓©äėĄ─ĖµŠ»Ż¼Ž┬łD╩Ū58ĄĮ╝ę┴„┐žĄ─Ēō├µŻ¼┐╔ęįū÷ĄĮĘ■äš╣Ø(ji©”)³c╝ēäeŻ¼ī”æ¬Ę■䚥─ĘĮĘ©╝ēäeŻ¼¼Fį┌╩Ū░┤├┐ĘųńŖĄ─ĘĮ╩ĮŻ¼═©▀^öĄō■┐s£p╔Žł¾Ż¼īŹĢršŲ╬šöĄō■ĪŻ
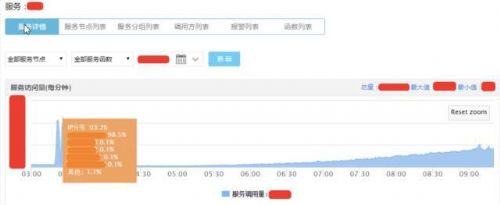
┴Ē═Ōę╗éĆŠ═╩Ū┘Yį┤öĄĄ─Ž▐ųŲŻ¼öĄō■ÄņĄ─┘Yį┤öĄę╗░ŃįOų├ę▓╩ŪķōųĄŻ¼░³└©ūŅąĪųĄ║═ųĄĪŻūŅąĪųĄų„ę¬╩ŪĮŌøQĖ▀ĘÕ═╗╚╗üĒ┼RĄ─Ģr║“Ż¼öĄō■Äņė▓╝■╚ń╣¹šµ▓╗ē“Ż¼┐╔ęį╠ßŪ░ŅAĘų┼õę╗▓┐Ęųė▓╝■ĪŻĄ─ė▓╝■ę▓╩Ūī”öĄō■ÄņĖ³║├Ą─▒ŻūoŻ¼╚ń╣¹öĄō■Äņ│÷å¢Ņ}┴╦Ż¼š¹éĆĘ■äš╗∙▒Š╔Žę▓Ģ■│÷å¢Ņ}ĪŻ
┴Ē═Ōę╗éĆ╩Ū╣żū„ŠĆ│╠öĄĄ─┐žųŲŻ¼ų„ę¬╩Ū═©▀^ŠĆ│╠─Żą═ĪŻ▒╚╚ńšfIOŠĆ│╠Ė·╬┤üĒĄ─öĄō■░³Ę┼ĄĮī”æ¬Ą─╣żū„ŠĆ│╠└’├µ╠Ä└ĒŻ¼═©▀^ī”æ¬Ą─ĘĮ╩ĮŽ╚░č╦∙ėąĄ─šłŪ¾Ę┼ĄĮę╗éĆī”Ž¾└’├µŻ¼╣żū„ŠĆ│╠į┘Å─ī”Ž¾└’├µ½@╚ĪŽÓæ¬Ą─╚╬äšĪŻ╬ęéāę▓ĮĶĶb┴╦ę╗ą®ūā╗»║═īŹ█`Ż¼├┐éĆŠĆ│╠ĮMĢ■ėąę╗éĆ╣żū„ī”³cŻ¼┐╔ęįįOų├ŽÓæ¬Ą─ąį─▄öĄŻ¼īŹ¼F┼õų├ČÓéĆŠĆ│╠ĮMŻ¼├┐éĆŠĆ│╠ĮMōĒėąūų╣Ø(ji©”)Įy(t©»ng)ę╗Ą─╣żū„ĻĀ┴ąŻ¼£p╔┘į┌Ė▀▓ó░l(f©Ī)ŪķørŽ┬Ą─ĖéĀÄĪŻī”ė┌ŠĆ│╠ĮM║═├┐éĆŠĆ│╠ĮM└’├µĄ─ŠĆ│╠öĄŻ¼¼Fį┌Č╝╩Ū┐╔ęįū÷ĄĮ┬ō║ŽĄ─┼õų├ĪŻ

╬ęéāū÷Ę■äš╗»Ą─Ģr║“Ż¼ļSų°╝▄śŗĄ─╔²╝ēĘ■äšöĄ┴┐Ģ■įĮüĒįĮČÓĪŻį┌┼┼▓ķå¢Ņ}Ą─Ģr║“Ż¼╠žäe╩Ūę╗ą®śI(y©©)äšĘŪ│ŻÅ═ļsĄ─Ę■䚯¼š¹éĆĄ─š{ė├µ£╩ŪĘŪ│ŻķLĄ─ĪŻų«Ū░ėĪŽ¾▒╚▌^╔Ņ┐╠Ż¼│÷üĒę╗éĆå¢Ņ}┼┼▓ķĢrķgĢ■╠žäeķLĪŻßśī”¼FĀŅ╬ęéāū÷┴╦Ę■äš╣żū„ŽĄĮy(t©»ng)Ż¼ų„ę¬╩Ū╗∙ė┌╚šųŠĄ─╩š╝»Ż¼╬ęéāķ_░l(f©Ī)┴╦ę╗éĆ╣½╣▓Ą─╚šųŠĮM╝■Ż¼║Ż┴┐Ą─╚šųŠ╔Žł¾Č╝┐╔ęįų¦│ųŻ¼├┐ĘųńŖĢ■░čŽÓæ¬Ą─šłŪ¾║═š{ė├ŽÓĻPĄ─ę╗ą®ą┼ŽóĮy(t©»ng)ę╗╔Žł¾ĄĮ╚šųŠ╩š╝»ŲĮ┼_ĪŻ¼Fį┌╗∙▒Š╔Ž║Ł╔w┴╦╦∙ė├Ą─╚½▓┐┐“╝▄Ż¼ūį蹥─Web┐“╝▄ĪóĘ■äš┐“╝▄Ż¼ęį╝░ŽÓæ¬Ą─┐═æ¶Č╦║═öĄō■ÄņĄ─ųąķg╝■Ż¼▀@ą®Č╝╩Ū═©▀^▓Õ╝■Ą─ĘĮ╩ĮŻ¼░č├┐éĆ┐“╝▄Ą─╚šųŠš{ė├Ą─ą┼ŽóĮy(t©»ng)ę╗╔Žł¾ĄĮ╚šŲĮ┼_Ż¼ū÷ę╗ą®īŹĢrĄ─š╣╩Šęį╝░║¾└m(x©┤)śI(y©©)äšš{ė├öĄō■Ą─Ęų╬÷ĪŻ
▀@╩Ū╬ęéāĄ─ą¦╣¹łDĪŻ
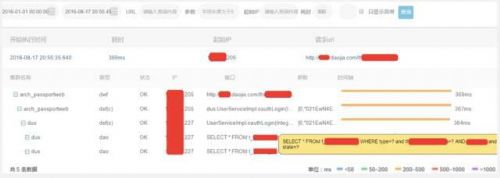
╬ęéā┐╔ęįū÷ĄĮĖ∙ō■▀@éĆšłŪ¾Ą─ģóöĄŻ¼▒╚╚ńšfŪ░Č╦ėąę╗╣Pėåå╬Ą─šłŪ¾Ż¼┐╔ęįĖ∙ō■ėåå╬Ą─ģóöĄęį╝░ė├æ¶IDĄ╚Ą╚ū÷ę╗ą®š{ė├Ą─Öz╦„Ż¼╠žäe╩Ū┼┼▓ķå¢Ņ}Ą─Ģr║“Ż¼│÷¼F«É│Ż╗“š▀šfĘ■䚥─šłŪ¾║─Ģr╠žäeķLĄ─Ģr║“Ż¼┐╔ęį║▄┐ņĄ─Å─║¾┼_Öz╦„ĄĮėąå¢Ņ}Ą─ę╗ą®š{ė├µ£Ż¼▀MČ°ū÷│÷ę╗ą®ā×(y©Łu)╗»ĪŻ
š{ė├Ė·█ÖŽĄĮy(t©»ng)Ż¼┤¾ų┬ųvę╗Ž┬ŽÓĻPĄ─╝╝ąg³cĪŻ╩ūŽ╚Š═╩Ūš¹éĆš{ė├µ£╬ęéāę¬Å─Ū░Č╦šŠ³cĄĮĘ■äšīėĪóöĄō■īėŻ¼š¹éĆš{ė├ĻPŽĄ╗“š▀š{ė├µ£Įo┤«ŲüĒŻ¼ų„ę¬ę└┘ćė┌ā╔éĆį¬╦žŻ║ę╗éĆ╩Ūėąę╗éĆ╚½ŠųĄ─š{ė├Ą─╣żū„IDŻ¼░č╬ęéā╦∙ėąĄ─š{ė├šłŪ¾═©▀^▀@éĆIDĮo┤«ŲüĒŻ¼▀@śėį┌Č©╬╗å¢Ņ}Ą─Ģr║“Ż¼┐╔ęį┼┼▓ķĄĮ├┐éĆš{ė├Łh(hu©ón)╣Ø(ji©”)ĪŻ┴Ē═Ō▀Ćėąę╗éĆš{ė├Ą─īė╝ēĻPŽĄŻ¼▒╚╚ńšfę╗éĆšŠ³c└’├µš{┴╦║├ÄūéĆĘ■䚯¼įOėŗ┴╦įu╝ēš{ė├ĻPŽĄĪŻ┴Ē═Ō▀@éĆĘ■äš▒Š╔Ēā╚▓┐š{┴╦Ž┬ė╬Ųõ╦¹Ę■䚯¼ę▓┐╔ęį║▄ĘĮ▒ŃĄ─═©▀^║¾┼_ŽĄĮy(t©»ng)┐┤Ą├ęŖĪŻ
ė╔ė┌╩ŪĘų▓╝╩ĮĄ─ŽĄĮy(t©»ng)Ż¼š¹éĆš{ė├µ£▓╗╩Ūį┌─│ę╗┼_Ę■äšŲ„╔Ž├µ┐╔ęį╚½▓┐╦č╝»Ą─ĄĮŻ¼═∙═∙╩Ū┐ńĘ■äšŲ„Ż¼ī”ė┌▓╗═¼Ę■äšŲ„ų«ķgš{ė├µ£Ą─öĄō■į§├┤śė═Ėé„?╚ń╣¹═¼ę╗┼_Ę■äšŲ„Ż¼═¼ę╗éĆ╠ōöMÖC└’├µĄ─Ę■äšĮŌøQš{ė├Ż¼╬ęéā╩Ū═©▀^ŠĆ╔Žūā┴┐╚źū÷Ą─▀@╝■╩┬ŪķĪŻ═©▀^ģfūhīė├µ╠žäe╩Ū┐ńĘ■äšŲ„š{ė├Ą─Ģr║“Ż¼░č▀@ą®öĄō■Ę┼į┌ģfūh└’├µŻ¼é„▌öĄĮ┴Ē═Ōę╗Č╦ĪŻ
┴Ē═Ōš{ė├µ£į┌═ŲÅVĄ─▀^│╠ųą░l(f©Ī)¼F┴╦ę╗éĆå¢Ņ}Ż¼«ö╬ęéā╚½┴┐═Ųš{ė├µ£Ą─Ģr║“öĄō■┴┐╠žäe┤¾ĪŻ╦∙ęį╬ęéāū÷┴╦╚½┴┐Ą─š{ė├µ£ŽÓĻPĄ─öĄō■▓╔╝»║═▓╔śėĄ─ĘĮ╩ĮŻ¼ī”ė┌║╦ą─Ę■äš╬ęéāĢ■ėą╚½┴┐ĪŻ▓╔śėę▓┐╔ęįĮŌøQ│÷┴╦å¢Ņ}Ą─Ģr║“┐╔ęį▒╚▌^┐ņ╦┘Ą─Č©╬╗Ż¼ę╗░ŃŪķørŽ┬│÷å¢Ņ}Ą─Ģr║“Ż¼Ģ■ėąę╗Č©Ą─čė└m(x©┤)ąįŻ¼š{ė├ę▓╩ŪŽÓī”▒╚▌^ļSÖCĄ─Ż¼╦∙ęį▓╔śė╩Ū┐╔ęį▓╔ĄĮėąå¢Ņ}Ą─öĄō■ĪŻ▀@╩Ūš{ė├Ė·█ÖŽĄĮy(t©»ng)ę╗ą®ŽÓĻPĄ─īŹ█`╣żū„ĪŻ
š{ė├Ė·█ÖŽĄĮy(t©»ng)┐╔ęį░l(f©Ī)¼F├┐ę╗┤╬š{ė├┐╔─▄┤µį┌Ą─å¢Ņ}Ż¼ę▓┐╔ęįęįłDą╬Ą─ĘĮ╩Į║▄┐ņĄ─┐┤ĄĮ╬ęéāŽļę¬ų¬Ą└Ą─ę╗ą®öĄō■Ż¼▀@╩Ūßśī”├┐ę╗┤╬š{ė├ĪŻ┴Ē═Ōßśī”š{ė├µ£Ż¼├┐╠ņĢ■ū÷ę╗éĆöĄō■╚½┴┐Ą─Ęų╬÷Ż¼ų„ꬥ──┐Ą─Š═╩Ūšf╬ęéāŽļų¬Ą└š¹éĆ╗“š▀šfęį╝»╚║×ķå╬╬╗Ż¼▀@éĆ╝»╚║Ž┬├µę└┘ćė┌──ą®Ž┬ė╬Ż¼╚╗║¾╬ęéāĮo──ą®╔Žė╬╠ß╣®ŽÓæ¬Ą─Ę■䚯¼▀@śė┐╔ęįĘ┤Ž“Ą─üĒ═ŲäėĘ■äš╝▄śŗĄ─ā×(y©Łu)╗»Ż¼ę“×ķėą┐╔─▄Ģ■│÷¼FŽ±čŁŁh(hu©ón)ę└┘ć╗“š▀šfš{ė├µ£╠žäeķLĪŻČ°š{ė├µ£╠žäeķLĄ─įŁę“Ż¼▒Š╔Ē┐╔─▄╩ŪśI(y©©)䚥─▓╗║Ž└ĒŻ¼╗“š▀šf▒Š╔ĒįOėŗĄ─Ģr║“ėąę╗ą®▓Ęųū÷Ą├▓╗╩Ū╠žäe║├Ż¼═©▀^Ę■äšę└┘ćęį╝░š{ė├µ£╔Žł¾Ą─öĄō■Ż¼╬ęéā┐╔ęį░l(f©Ī)¼F╝▄śŗīė├µĄ─å¢Ņ}Ż¼▀MČ°Ę┤═Ų╝▄śŗĄ─ā×(y©Łu)╗»ĪŻ
ūŅ║¾╩Ūę╗éĆąĪĮYŻ¼Į±╠ņų„ųvĄ─ā╚╚▌ų„ę¬╩Ū×ķ╩▓├┤╬ęéāę¬ū÷Ę■äšų╬└Ēęį╝░58ĄĮ╝ę╩Ūį§śėū÷Ą─ĪŻĘ■äšų╬└Ēę╗░Ń╩ŪĢ■░ķļSĘ■äš╗»╚źū÷ę╗ą®Ę■䚥─▓ĘųŻ¼─┐Ą─Š═╩Ū×ķ┴╦Ė³║├Ą─ĮŌ±ŅŻ¼×ķ┴╦Ė³║├Ą─ū÷Ę■äšöU╚▌Ą╚Ą╚ĪŻ
Ę■äš░l(f©Ī)▓╝ų„ę¬ĮŌøQĄ─╩ŪĘ■䚥žųĘĄ─═Ė├„╗»Ż¼ęį╝░╗∙ė┌ūóāįųąą─Ą─╝»ųą╣▄└ĒĪŻ
┬Ęė╔║═╚▌Õeų„ę¬╩ŪĮŌøQ┐╔ė├ąįęį╝░Ę■äšžō▌dĄ─å¢Ņ}ĪŻ
┴„┐ž║═ĖµŠ»ų„ę¬╩Ū×ķ┴╦ū÷▀^▌d▒ŻūoĪŻ
öĄō■ÄņĄ─µ£ĮėöĄŻ¼ŠĆ│╠öĄĪó┘Yį┤öĄĄ─┐žųŲŻ¼ę▓╩Ūī”Ę■äšū÷Ė³║├Ą─▒Żūoęį╝░┐╔ęįį§śėūī╬ęéāĄ─Ę■äšĖ³║├Ą─Ēææ¬┐═æ¶Č╦Ą─šłŪ¾Ż¼į§śė╠ßĖ▀ķ]Łh(hu©ón)┴┐ĪŻ
ūŅ║¾ę╗³c╩Ūš{ė├Ė·█ÖŽĄĮy(t©»ng)Ż¼├µ┼Rų°║▄ČÓ▓Ęų│÷üĒĄ─╬óĘ■䚯¼╦³éāų«ķgĄ─š{ė├ĻPŽĄ╠žäeÅ═ļsŻ¼×ķ┴╦Ė³┐ņ╦┘Ą─Č©╬╗ŠĆ╔Žå¢Ņ}╦∙ęį╬ęéāėą┴╦š{ė├Ė·█ÖŽĄĮy(t©»ng)Ż¼╗∙ė┌š{ė├Ė·█ÖŽĄĮy(t©»ng)Ż¼┐╔ęįĖ∙ō■š{ė├ĻPŽĄ╚źĘ┤═Ų╝▄śŗĄ─ā×(y©Łu)╗»ĪŻ
ĻPė┌APMConŻ║
2016ųąć°æ¬ė├ąį─▄╣▄└Ē┤¾Ģ■(║åĘQAPMCon 2016)ė┌8į┬18╚šų┴19╚šį┌▒▒Š®ą┬įŲ─Ž╗╩╣┌╝┘╚šŠŲĄĻ┬Īųžš┘ķ_ĪŻAPMConė╔┬ĀįŲĪóśO┐═░Ņ║═InfoQ┬ō║Žų„▐kĄ─ū„×ķć°ā╚APMŅIė“ė░Ēæ┴”Ą─╝╝ąg┤¾Ģ■Ż¼┼e▐kĄ─APMConęį““īäėæ¬ė├╝▄śŗā×(y©Łu)╗»┼cäō(chu©żng)ą┬”×ķų„Ņ}Ż¼Š█Į╣«öŪ░ūŅ×ķ¤ßķTĄ─ęŲäėČ╦ĪóWebČ╦║═ServerČ╦Ą─ąį─▄▒O(ji©Īn)┐ž║═╣▄└Ē╝╝ągŻ¼š¹éĆĢ■ūhįOų├░³║¼┴╦Ż║ąį─▄┐╔ęĢ╗»ĪóĘ■äšČ╦▒O(ji©Īn)┐žīŹ█`Īó▀\ŠSūįäė╗»ĪóöĄō■Äņąį─▄ā×(y©Łu)╗»ĪóAPMįŲĘ■äš╝▄śŗ║═HTML5š{ā×(y©Łu)īŹ█`Ą╚įÆŅ}Ż¼ų┬┴”ė┌═ŲäėAPMį┌ć°ā╚Ą─│╔ķL┼c░l(f©Ī)š╣ĪŻ