

üå±R▀dAWS╩ūŽ»įŲėŗ(j©¼)╦Ń╝╝ąg(sh©┤)ŅÖå¢ ┘M(f©©i)┴╝║Ļė┌╗∙ė┌įŲ╝▄śŗ(g©░u)Ą─ąį─▄ā×(y©Łu)╗»īŻł÷░l(f©Ī)▒Ē┴╦Ņ}×ķĪČAWS įŲėŗ(j©¼)╦Ńų«╔ŽLinuxīŹ(sh©¬)└²Ą─ā×(y©Łu)╗»ĪĘĄ─č▌ųvŻ¼¼F(xi©żn)ł÷ĘųŽĒ┴╦AWS ╔ŽLinux īŹ(sh©¬)└²Ą─╔ŅČ╚ā×(y©Łu)╗»║═īŹ(sh©¬)█`Ż¼▀@ī”ė┌įŲėŗ(j©¼)╦ŃĄ─Č°čį╩ŪūŅ╗∙ĄA(ch©│)Ą½ģs╩Ū▓╗┐╔╚▒╔┘Ą─ę╗Łh(hu©ón)ĪŻ

ęįŽ┬×ķč▌ųvīŹ(sh©¬)õøŻ║
┘M(f©©i)┴╝║ĻŻ║┤¾╝ę║├Ż¼║▄Ė▀┼dĖ·┤¾╝ęĘųŽĒę╗ą®╬ęūŅĮ³ĻP(gu©Īn)ą─Ą─įÆŅ}ĪŻį┌įŲėŗ(j©¼)╦Ń╔Ž╬ęéāĢ■╩╣ė├║▄ČÓĄ─▓┘ū„ŽĄĮy(t©»ng)Ż¼Linux╩Ū╬ęéāĘŪ│Ż╩ņŽżĪó╩╣ė├┴┐ĘŪ│Ż┤¾Ą─ŽĄĮy(t©»ng)Ż¼Ą½╩Ū╚ń║╬ī”▀@éĆ(g©©)▓┘ū„ŽĄĮy(t©»ng)▀M(j©¼n)ąąā×(y©Łu)╗»Ż¼╩Ū┤¾╝ę├µ┼RĄ─å¢Ņ}ĪŻLinuxĄ─Üv╩Ę▒╚▌^ėŲŠ├Ż¼Ą½╩Ūį┌įŲėŗ(j©¼)╦Ńų«╔ŽĄ─ā×(y©Łu)╗»ėąę╗ą®ąĶę¬╠žäeūóęŌĄ─ĄžĘĮŻ¼ę▓╩ŪĮ±╠ņ╬ęŽļĖ·┤¾╝ęĘųŽĒĄ─ÄūéĆ(g©©)įÆŅ}ĪŻ
╠ߥĮįŲėŗ(j©¼)╦Ń╬ęŽļŽ╚ĮķĮBę╗Ž┬AWSŻ¼┤¾╝ę┐╔─▄ų¬Ą└AWS╩ŪįŲėŗ(j©¼)╦ŃĘ■äš(w©┤)Ą─╠ß╣®š▀Ż¼ĄĮ─┐Ū░×ķų╣AWSį┌╚½Ū“ėą13éĆ(g©©)ģ^(q©▒)ė“Ż¼Ųõųą░³└©35éĆ(g©©)┐╔ė├ģ^(q©▒)Ż¼ėą56éĆ(g©©)▀ģŠēšŠ³c(di©Żn)Ż¼▀@ą®śŗ(g©░u)│╔┴╦╚½Ū“įŲėŗ(j©¼)╦ŃĄ─╗∙ĄA(ch©│)╝▄śŗ(g©░u)Ż¼Ę■äš(w©┤)ė┌╚½Ū“190éĆ(g©©)ć°╝ęĪŻ
į┌▀^╚źĄ─╩«─Ļ└’═©▀^▀@śėĄ─░l(f©Ī)š╣Ż¼AWS¼F(xi©żn)į┌╦∙╠ß╣®Ą─Ę■äš(w©┤)ĘČć·╩ŪĘŪ│ŻÅVĘ║Ą─Ż¼║Ł╔wĄ─ĘNŅÉ▓╗āH░³└©┴╦ėŗ(j©¼)╦ŃĪóŠW(w©Żng)Įj(lu©░)Īó┤µā”ĪóöĄ(sh©┤)ō■(j©┤)ÄņĪó┤¾öĄ(sh©┤)ō■(j©┤)Īó╚╦╣żųŪ─▄Ż¼▀Ć░³└©┴╦Ž±░▓╚½Ż¼╔§ų┴Ž±SaaSĄ╚Ą╚ę╗ą®ą┬Ą─įŲėŗ(j©¼)╦ŃĄ─ŅI(l©½ng)ė“ĪŻ
į┌Į±─Ļ8į┬6╠¢░l(f©Ī)▓╝Ą─įŲėŗ(j©¼)╦ŃIaaS─¦┴”Ž¾Ž▐└’├µŻ¼AWSėų╠Äė┌ł¾(b©żo)ĖµĄ─Į^ī”ŅI(l©½ng)Ž╚╬╗ų├ĪŻį┌▀@éĆ(g©©)ł¾(b©żo)Ėµ│÷¼F(xi©żn)Ą─6─ĻĢr(sh©¬)ķg└’Ż¼├┐┤╬AWSČ╝╠Äė┌Į^ī”ŅI(l©½ng)Ž╚Ą─╬╗ų├Ż¼▀@éĆ(g©©)ł¾(b©żo)Ėµę▓┤·▒Ē┴╦AWSį┌š¹éĆ(g©©)įŲėŗ(j©¼)╦Ń╩ął÷Ą─╬╗ų├ĪŻ
╚ń╣¹╩╣ė├▀^AWSĄ─╚╦Ż¼┐ų┼┬Ą┌ę╗éĆ(g©©)Įėė|Ą─«a(ch©Żn)ŲĘČ╝╩ŪAWS╦∙╠ß╣®Ą─ÅŚąį╠ōöMĘ■äš(w©┤)Ų„Ż¼╬ęéāĘQų«×ķEC2Ż¼▀@éĆ(g©©)«a(ch©Żn)ŲĘę▓╩Ū╬ęĮ±╠ņšäĄ─ųž³c(di©Żn)įÆŅ}Ż¼ę▓Š═╩Ū╚ń║╬ßśī”▀@śėĄ─Łh(hu©ón)Š│▀M(j©¼n)ąąā×(y©Łu)╗»ĪŻ
┤¾╝ęČ╝┴╦ĮŌį┌įŲėŗ(j©¼)╦ŃĄ─Łh(hu©ón)Š│└’├µ░³└©į┌öĄ(sh©┤)ō■(j©┤)ųąą─└’├µĢ■ėą║▄ČÓ╬’└ĒĘ■äš(w©┤)Ų„Ż¼Ę■äš(w©┤)Ų„ų«╔Ž═©▀^╠ōöM╗»Ą─╝╝ąg(sh©┤)Ģ■╠ß╣®įSįSČÓČÓĄ─╠ōöMÖC(j©®)Ż¼╚ń║╬╩╣ė├▀@ą®╠ōöMÖC(j©®)Ą─┘Yį┤Ż¼ūī╦³Ė³║├Ą─Ę■äš(w©┤)ė┌╬ęéāĄ─æ¬(y©®ng)ė├Ż¼▀@╩Ū╬ęéā├µ┼RĄ─ę╗éĆ(g©©)║▄¼F(xi©żn)īŹ(sh©¬)Ą─å¢Ņ}ĪŻ
╗žŅÖŲüĒ▀@śėĄ─╝╝ąg(sh©┤)░l(f©Ī)š╣ėą│¼▀^╩«─ĻĄ─Ģr(sh©¬)ķgŻ¼╩«─ĻŪ░Ą┌ę╗┤·EC2«a(ch©Żn)ŲĘĘNŅÉ▒╚▌^å╬ę╗Ż¼Č°Ūęąį─▄ŽÓī”▒╚▌^╚§ąĪĪŻĄ½╩Ū═©▀^╩«─ĻĄ─░l(f©Ī)š╣Ż¼ė╚Ųõ╩Ūį┌▀^╚ź╚²─Ļ└’░l(f©Ī)š╣╦┘Č╚ĘŪ│Ż┐ņŻ¼Äū║§├┐─ĻČ╝ėą║▄ČÓą┬ŅÉą═╠ōöMÖC(j©®)Ą─┘Yį┤Ģ■░l(f©Ī)▓╝│÷üĒĪŻ
├µī”▀@śėĄ─Łh(hu©ón)Š│Ż¼╬ęéā╩╣ė├Ą─ėŗ(j©¼)╦ŃÖC(j©®)┘Yį┤╚ń┤╦žSĖ╗Ż¼╬ęéā┐╔ęį═©▀^AWSŁh(hu©ón)Š│╩╣ė├├Ō┘M(f©©i)Ą─▓┘ū„ŽĄĮy(t©»ng)Ż¼╬ęéāĘQų«×ķAmazon Machine ImageŻ¼▀@ą®▓┘ū„ŽĄĮy(t©»ng)░³└©Amazon LinuxĪóCentOSĪóFreeBSDĪóUbuntuĪóDebianĄ╚Ż¼═¼śėę▓ėą┤¾┴┐ĖČ┘M(f©©i)Ą─▓┘ū„ŽĄĮy(t©»ng)Ż¼░³└©Windows ServerĪóRed Hat Enterprise Linux ĪóSUSE Linux Enterprise ░µ▒ŠĄ╚Ą╚ĪŻ═¼śė╩╣ė├AWS╠ß╣®Ą─Marketplace┘Yį┤Ż¼─Ń┐╔ęį┤¾┴┐Ą─╩╣ė├Ą┌╚²ĘĮ╔§ų┴╔ńģ^(q©▒)╠ß╣®Ą─Ė„ĘNLinux░µ▒Š║═Ęų░l(f©Ī)Ą─Įķ┘|(zh©¼)ĪŻį┌ Marketplace└’├µ╦∙ėąĄ─Linux Image┐éöĄ(sh©┤)╩Ū1738éĆ(g©©)Ż¼Äū║§║Ł╔w┴╦╦∙ėąų„┴„Ą─Linux░µ▒ŠĪŻ
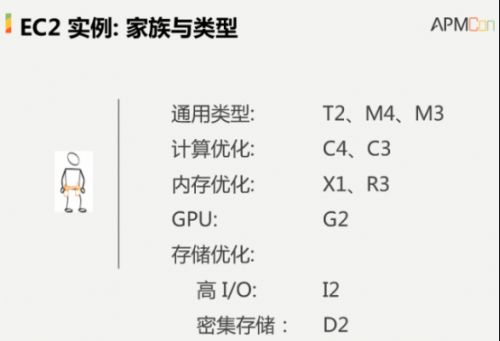
╦∙ėąĄ─EC2«a(ch©Żn)ŲĘ░³║¼į┌╩«éĆ(g©©)┤¾Ą─╝ęūÕ«a(ch©Żn)ŲĘ└’├µŻ¼▀@ą®╝ęūÕ«a(ch©Żn)ŲĘėąĖ„ūį▓╗═¼Ą──┐Ą─Ż¼Ęųäe▀mė├ė┌ėŗ(j©¼)╦Ńā×(y©Łu)╗»Īóā╚(n©©i)┤µā×(y©Łu)╗»ĪóGPUĪó┤µā”ā×(y©Łu)╗»Ą╚Ą╚ĪŻŲõųąę╗ą®«a(ch©Żn)ŲĘ┤·▒Ē┴╦▀@éĆ(g©©)ŅI(l©½ng)ė“└’├µūŅĖ▀Ą─╝ēäeŻ¼▒╚╚ńūŅą┬░l(f©Ī)▓╝Ą─S1Š═╠ß╣®┴╦2TBā╚(n©©i)┤µĄ─╠Ä└Ē─▄┴”Ż¼▀@ą®▓╗═¼Ą─ÖC(j©®)Ų„┐╔ęįØMūŃ┤¾╝ę▓╗═¼│╠Č╚Ą─ąĶŪ¾ĪŻ

Į±╠ņĄ─įÆŅ}╩Ūć·└@EC2 LinuxŁh(hu©ón)Š│Ą─ā×(y©Łu)╗»Ż¼Å─▀@éĆ(g©©)║åå╬Ą─╩ŠęŌłD┐╔ęį┐┤ĄĮŻ¼╬ęéā─▄ē“╩╣ė├ĄĮĄ─ų„ꬊ═╩ŪGuestĪóOSĄ╚Ż¼╦³éā▀\(y©┤n)ąąį┌ę╗éĆ(g©©)╠ōöMīėų«╔ŽŻ¼ų«Ž┬╩Ū╬’└ĒĄ─▓┘ū„ŽĄĮy(t©»ng)ĪŻ├µī”▀@śėĄ─Łh(hu©ón)Š│Ż¼ā×(y©Łu)╗»ĘĮ╩ĮĖ·╬ęéāé„Įy(t©»ng)╩ņŽżĄ─Linuxā×(y©Łu)╗»ėą║▄ČÓĄ─▓╗═¼Ż¼▀@ę▓╩Ū╬ęĮ±╠ņÅŖ(qi©óng)š{(di©żo)Ą─ūŅųžę¬Ą─ę╗³c(di©Żn)ĪŻ
╗žĄĮā×(y©Łu)╗»Ą─å¢Ņ}Ż¼╬ęéā╩ūŽ╚ę¬øQČ©ā×(y©Łu)╗»Ą──┐Ą─ĄĮĄū╩Ū╩▓├┤Ż┐╩ŪøQČ©Ė─▀M(j©¼n)╬ęéāĄ─ąį─▄Ż¼─Ūąį─▄ėų╩Ū╩▓├┤ęį╝░╚ń║╬Č©┴x╦³Ż┐▀@╩Ū╩ūŽ╚▒žĒÜę¬╗ž┤Ą─å¢Ņ}ĪŻė╔ė┌╬ęéāĄ─ąĶŪ¾▓╗═¼Ż¼ī”ąį─▄Ą─ę¬Ū¾ėą║▄┤¾Ą─▓Ņ«ÉĪŻ╦∙ęįøQČ©ā×(y©Łu)╗»ų«Ū░Ž╚Å─å¢Ņ}Ą─ęĢĮŪ│÷░l(f©Ī)Ż¼├„┤_─ŃĄ─ąĶŪ¾╩Ū╩▓├┤ĪŻ═©│ŻüĒ┐┤ąį─▄Ą─▒Ē¼F(xi©żn)╚ĪøQė┌║▄ČÓę“╦žŻ¼▀@ą®ę“╦ž┐╔ęįÜw╝{×ķ╚²éĆ(g©©)┤¾Ą─ĘĮ├µŻ¼ŽĄĮy(t©»ng)Ēææ¬(y©®ng)Ģr(sh©¬)ķgĪó═╠═┬┴┐Īóę╗ų┬ąįĪŻ«ö(d©Īng)╚╗ąį─▄▓╗āHāH░³└©▀@ą®Ż¼╬ęĮ±╠ņšäĄĮĄ─ų╗╩Ū═©ė├Ą─ĘĮ├µĪŻ

ė░Ēæąį─▄Ą─ę“╦žÅ─ÅV┴x╔ŽüĒšfĘŪ│ŻČÓŻ¼Ą½╩Ūć·└@ų°▓┘ū„ŽĄĮy(t©»ng)▀@éĆ(g©©)Łh(hu©ón)Š│üĒ┐┤Ż¼ė░Ēæąį─▄ę“╦ž░³└©ÄūéĆ(g©©)ĘĮ├µŻ¼Ą┌ę╗éĆ(g©©)Š═╩ŪCPUŻ¼CPU▓Õ▓█Ą─öĄ(sh©┤)┴┐Īó║╦Ą─öĄ(sh©┤)┴┐Ą╚Ą╚ī”CPUĄ─▒Ē¼F(xi©żn)ėą║▄┤¾Ą─ė░ĒæĪŻŲõ┤╬╩Ūā╚(n©©i)┤µŻ¼ā╚(n©©i)┤µ╚▌┴┐Ą─ČÓ╔┘ų▒Įėė░ĒæĄĮ╬ęéā╩╣ė├Ą─┘Yį┤╦∙─▄│ąō·(d©Īn)Ą─╠Ä└Ē─▄┴”ĪŻŠW(w©Żng)Įj(lu©░)Ą─ĦīÆĪó░³╦┘┬╩ę▓Ģ■ī”ŠW(w©Żng)Įj(lu©░)Ūķørėą║▄┤¾Ą─ųŲ╝sĪŻ┤┼▒PĄ─ŪķørŻ¼░³└©═╠═┬┴┐║═├┐├ļńŖ═Ļ│╔Ą─▌ö│÷/▌ö╚ļČ╝╩Ū║▄┤¾Ą─ė░ĒæŻ¼Į±╠ņ╬ęéāŠ═╩Ūć·└@▀@ÄūéĆ(g©©)ĘĮ├µš╣ķ_ĪŻ│²┤╦ų«═Ō▀Ćėą║▄ČÓę“╦žČ╝Ģ■ī”ąį─▄«a(ch©Żn)╔·ė░ĒæŻ¼Ą½▓╗į┌╬ęéāĄ─╠ĮėæĘČć·ų«ā╚(n©©i)ĪŻ
šäĄĮįŲėŗ(j©¼)╦ŃĄ─ąį─▄å¢Ņ}▒žĒÜę¬ÅŖ(qi©óng)š{(di©żo)ę╗³c(di©Żn)Š═╩Ū┘Yį┤Ą─└¹ė├┬╩Ż¼į┌é„Įy(t©»ng)ßśī”╬’└ĒÖC(j©®)Ą─ā×(y©Łu)╗»└’├µ▓╗╩Ū╠žäeį┌ęŌ┘Yį┤└¹ė├┬╩Ż¼į┌Ą═└¹ė├┬╩Ą─ŪķørŽ┬╬ęéā▀ĆĖ`Ž▓Ż¼ę“?y©żn)ķ▀Ć╠Äį┌▒╚▌^║├Ą─ĀŅæB(t©żi)ĪŻįŲėŗ(j©¼)╦ŃĄ─Łh(hu©ón)Š│Ż¼øQČ©┴╦įŲėŗ(j©¼)╦ŃĄ─│╔▒Š╩ŪÅŚąį┐╔ūāĄ─Ż¼╚ń╣¹▓╗─▄║▄║├Ą─└¹ė├┘Yį┤Ż¼╩╣┤¾┴┐┘Yį┤ķeų├Ż¼─│ĘNęŌ┴x╔ŽĢ■«a(ch©Żn)╔·śO┤¾Ą─└╦┘M(f©©i)ĪŻ╦∙ęįī”įŲėŗ(j©¼)╦ŃŁh(hu©ón)Š│Ž┬Ą─ā×(y©Łu)╗»üĒšfŻ¼╩ūŽ╚ę¬┐╝æ]Ą─╩Ū╚ń║╬╠ßĖ▀╬ęéā┘Yį┤Ą─└¹ė├┬╩ĪŻÅ─▀@éĆ(g©©)ĮŪČ╚│÷░l(f©Ī)╬ęĄ─Į©ūh╩ŪŻ¼▀xō±║├Ą─įŲėŗ(j©¼)╦ŃĄ─īŹ(sh©¬)└²Š═Ą╚ė┌ā×(y©Łu)╗»Ż¼╚ń╣¹▀xō±║═─ŃŽÓŲź┼õĄ─īŹ(sh©¬)└²Š═Ģ■ūŅ┤¾│╠Č╚░l(f©Ī)ō]─ŃĄ─┘Yį┤Ż¼╩╣╬ęéāĄ─│╔▒Šį┌║Ž└ĒĄ─ĘČć·ā╚(n©©i)Ż¼▓óŪę╬┤üĒļSų°╬ęéāąĶŪ¾Ą─▓╗öÓį÷ķLŻ¼╬ęéāĄ─│╔▒Šę▓Ģ■š{(di©żo)š¹Ż¼▓╗Ģ■ūī╬ęéāĄ─├┐ę╗ĘųÕX╗©į┌▓╗▒žę¬Ą─ĄžĘĮĪŻ

─Ū╚ń║╬▀xō±īŹ(sh©¬)└²─žŻ┐śI(y©©)ā╚(n©©i)ėą║▄ČÓĮø(j©®ng)“×(y©żn)║═ĘĮĘ©Ż¼▀@ÅłłD╩ŪNetflixĘŅ½I(xi©żn)ĮośI(y©©)ā╚(n©©i)Ą─╦¹éāūį╝║▀xō±īŹ(sh©¬)└²Ą─┴„│╠łDŻ¼ę└ō■(j©┤)▓╗═¼Ą─ąĶŪ¾└¹ė├▀@éĆ(g©©)┴„│╠łDŠ═┐╔ęįį┌×ķöĄ(sh©┤)▒ŖČÓĄ─ AWSīŹ(sh©¬)└²ŅÉą═«ö(d©Īng)ųą▀xō±▀m║Ž─ŃĄ─┘Yį┤ĪŻ▀@ą®┘Yį┤ŲõīŹ(sh©¬)▀Ć╩ŪĘŪ│ŻÅ═(f©┤)ļsĄ─Ż¼▓╗āHāH╩Ū╠ōöMÖC(j©®)║Ł╔wĄ─║¼┴xŻ¼ęįEC2 C4īŹ(sh©¬)└²×ķ└²Ż¼īŹ(sh©¬)ļH╩Ūßśī”Intel E5-2666 v3 CPUČ©ųŲĄ─ę╗┐Ņ«a(ch©Żn)ŲĘŻ¼╦Ń╩Ūę╗┤·├µŽ“ėŗ(j©¼)╦Ńā×(y©Łu)╗»Ą─īŹ(sh©¬)└²Ż¼Ė³═©ė├Ą─ŅÉą═ĪŻĄ½╩Ū×ķ┴╦ĮŌøQ▀@éĆ(g©©)ŅÉą═ę▓ū÷┴╦║▄ČÓā×(y©Łu)╗»Ż¼▒╚╚ńßśī”P-state║═C-state ▀M(j©¼n)ąą┴╦Č©ųŲ╗»Ą─┼õų├╠Ä└ĒĪŻP-state║═C-stateīŹ(sh©¬)ļH╔Ž╩ŪCPU APCIĄ─┐žųŲŻ¼øQČ©┴╦CPU╩Ū╠Äė┌Ą═╣”║─Ą─ĀŅæB(t©żi)▀Ć╩Ū╠Äė┌ę╗éĆ(g©©)Å─C0ĄĮCN▓╗═¼▀\(y©┤n)ąąĀŅæB(t©żi)╠Ä└Ē─▄┴”Ą─ūā╗»Ż¼┐╔ęį╩╣╬ęéāĄ─Ę■äš(w©┤)Ų„į┌─▄║─║═ąį─▄ų«ķg▒Ż│ųę╗éĆ(g©©)║Ž└ĒĄ─┐žųŲĪŻ═¼śė├┐ę╗┐ŅEC2Ą─īŹ(sh©¬)└²ėą▓╗═¼Ą─ą═╠¢Ż¼ėą▓╗═¼Ą─╠Ä└Ē─▄┴”Ż¼Å─largeĄĮ8xlarge╠ß╣®┴╦▓╗═¼Ą─╠Ä└Ē─▄┴”ĪŻ
EC2Ą─╝╝ąg(sh©┤)╠žąį└’ėąę╗ą®╩ŪąĶę¬ūī┤¾╝ę┴╦ĮŌŻ¼▓óŪę┐╔ęįæ¬(y©®ng)ė├▀@ą®╝╝ąg(sh©┤)▀M(j©¼n)ąąā×(y©Łu)╗»Ż¼╬ę┤¾Ė┼┴ą┼e┴╦ęįŽ┬▀@ą®ā╚(n©©i)╚▌ĪŻ
•CPU ųĖ┴Ņ║╦▒Żūo(h©┤)Ą╚╝ēĪŻī”ė┌X86▀@┐ŅCPU┤¾╝ę▒╚▌^ŪÕ│■╩ņŽżŻ¼▀@┐Ņ╝▄śŗ(g©░u)ėą├„’@Ą─╠žš„Ż¼Š═╩ŪųĖ┴Ņ║╦Ą─▒Żūo(h©┤)Ą╚╝ēŻ¼Č°Ūę▓╗─▄į┌ė├æ¶─Ż╩ĮŽ┬ł╠(zh©¬)ąą╠žÖÓ(qu©ón)ųĖ┴ŅüĒ▒Żūo(h©┤)ŽĄĮy(t©»ng)Ż¼æ¬(y©®ng)ė├│╠ą“═©▀^syscallīŹ(sh©¬)¼F(xi©żn)ā╚(n©©i)║╦š{(di©żo)ė├Ą─═Ļ│╔ĪŻ▒╚╚ń╬ęéāßśī”ę╗éĆ(g©©)WebĘ■äš(w©┤)Ų„Ż¼╩╣ė├straceŠ═┐╔ęį┐┤ĄĮ▓╗═¼Ą─š{(di©żo)ė├Ż¼ėąą¦Ą─£p╔┘▀@ą®š{(di©żo)ė├┐╔ęį├„’@╠ß╔²ąį─▄ĪŻ
•┴Ē═Ōę╗éĆ(g©©)╝╝ąg(sh©┤)╠ž³c(di©Żn)Š═╩ŪIntel VT-xŻ¼į┌2005─Ļ▀@┐Ņ╝╝ąg(sh©┤)│÷¼F(xi©żn)ų«Ū░Ż¼╬ęéāĄ─╠ōöM╗»ų„ę¬╩╣ė├PVĄ──Ż╩ĮŻ¼PV─Ż╩Į┤µį┌║▄ČÓ▓╗ūŃŻ¼▒╚╚ńšfąĶę¬┤®═ĖVMMŻ¼į÷╝ė┴╦čė▀tŻ¼ŽĄĮy(t©»ng)š{(di©żo)ė├Ą─ķ_õNęį╝░ŠW(w©Żng)Įj(lu©░)║═┤µā”ŽĄĮy(t©»ng)Ą─ąį─▄ķ_õNŽÓī”▒╚▌^┤¾Ż¼╦∙ęį─ŪĢr(sh©¬)║“╬ęéāī”╠ōöM╗»Ą─╝╝ąg(sh©┤)ėą║▄ČÓŅÖæ]ĪŻĄ½╩Ūį┌2005─Ļė╔ė┌Intelį÷╝ė┴╦▀@éĆ(g©©)╠žąįŻ¼╬ęéā│÷¼F(xi©żn)┴╦ą┬Ą─▀xō±Ż¼╩╣ė├ė▓╝■▌oų·Ą─╠ōöM╗»ØMūŃ┴╦ąį─▄Ą─╠ß╔²ĪŻė╚Ųõ╩Ū└¹ė├PV driver║═HVMŽÓĮY(ji©”)║ŽŻ¼Ū╔├ŅĮŌøQ┴╦╠Ä└Ē▌^┬²Ą─▓┘ū„Ż¼Å─┤╦ų«║¾╬ęéāĄ─╠ōöM╗»▓┼┤¾Ę┼«É▓╩▒╗śI(y©©)ā╚(n©©i)ÅVĘ║Įė╩▄ĪŻ
•Xen ╠ōöM╗»─Ż╩ĮĪŻ┤¾╝ęų¬Ą└XenĄ─ĘĆ(w©¦n)Č©░µ▒Š╩Ū4.7Ż¼╦³╠ß╣®┴╦╬ÕĘN╠ōöM╗»ĘĮ╩ĮŻ¼░³└©HVMĪóPV-HVMĪóPV driver HVMĪóPVHĄ╚Ą╚╬ÕĘN▓╗═¼Ą─ŅÉą═Ż¼ī”æ¬(y©®ng)ĄĮAWS EC2«a(ch©Żn)ŲĘ╔ŽŻ¼╬ęéā╦∙šfĄ─HVMŲõīŹ(sh©¬)Ą╚ār(ji©ż)ė┌PVHVMŻ¼Ū░╠ß╩ŪLinuxkernelų¦│ųĪŻ┴Ē═Ōį┌AWSĄ─ŠW(w©Żng)šŠ╔Ž─ŃĢ■┐┤ĄĮę▓Ģ■┤µį┌PVĄ─├Ķ╩÷Ż¼▀@Š═Ą╚ār(ji©ż)ė┌Xen PVĄ──Ż╩ĮĪŻ┐éĮY(ji©”)ŲüĒŻ¼╬ęéāį┌AWSŠW(w©Żng)šŠ╔Ž─▄ē“┐┤ĄĮĄ─╦∙ėąĄ─░Ė└²└’├µŻ¼ąį─▄ūŅ║├Ą├Š═╩ŪHVMĄ─Xen░µ▒ŠŻ¼ī”æ¬(y©®ng)Ą─Š═╩ŪPVHVMĪŻÅ─╬┤üĒĄ─░l(f©Ī)š╣üĒ┐┤Ż¼ļSų°╝╝ąg(sh©┤)Ą─▓╗öÓ▀M(j©¼n)▓ĮŻ¼╠ōöM╗»╝╝ąg(sh©┤)ę▓į┌▓╗öÓ╠ß╔²Ż¼╬┤üĒ┐╔─▄┐┤ĄĮĄ─ąį─▄ŅA(y©┤)Ų┌▒╚▌^║├Ą─Š═╩ŪPVHĪŻ
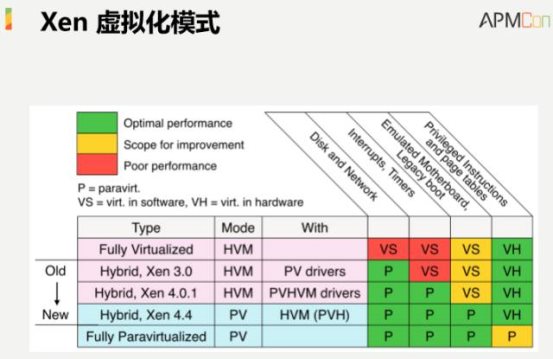
▀@ÅłłD└’╬ęÜw╝{┴╦äé▓┼šäĄĮĄ─ŪķørŻ¼«ö(d©Īng)╚╗▀@éĆ(g©©)░µ▒ŠŽÓī”└Ž┴╦ę╗³c(di©Żn)Ż¼łD╔Ž│╩¼F(xi©żn)Ą─╩Ū4.4░µ▒ŠŻ¼─┐Ū░╩Ū4.7░µ▒ŠŻ¼Ą½┐é¾wĄ─Ė±Šųø]ėą╠½┤¾Ą─ūā╗»ĪŻ─┐Ū░╩╣ė├▒╚▌^ČÓĄ─╩Ū PVHVMĄ──Ż╩ĮŻ¼╬┤üĒ┐╔─▄Ģ■▀^Č╔ĄĮPVHĄ─ł÷Š░└’├µĪŻ═©▀^ÄūéĆ(g©©)▓╗═¼Ą─ŠSČ╚┐╔ęį┐┤ĄĮŻ¼PVH┤·▒Ē┴╦╬┤üĒ╦┘Č╚ūŅ║├Ą─ĀŅæB(t©żi)ĪŻ
•┴Ē═Ōę╗éĆ(g©©)╠žąį╩Ūå╬Ė∙ I/O ╠ōöM╗»ę▓Š═╩ŪSR-IOVŻ¼▀@éĆ(g©©)╠žąįĄ─│÷¼F(xi©żn)╩Ū×ķ┴╦ĮŌøQŠW(w©Żng)Įj(lu©░)Ą─╠žąįŻ¼╠ōöM╗»Ģ■ī”ŠW(w©Żng)Įj(lu©░)ąį─▄«a(ch©Żn)╔·ōp║─ĪŻė┌╩ŪIntelßśī”▀@ĘNł÷Š░╠ß╣®┴╦ÄūéĆ(g©©)ĘĮ░ĖŻ¼īóPCIeĄ─įO(sh©©)éõ╣▓ŽĒĮo╬ęéā├┐ę╗éĆ(g©©)VMŻ¼─│ĘNęŌ┴x╔ŽŠ═ĮŌøQ┴╦┤®═ĖĄ─å¢Ņ}Ż¼╩╣Ą├╬ęéāĄ─ VM┐╔ęįų▒ĮėįLå¢PCIeĄ─įO(sh©©)éõŻ¼Š═╩ŪŠW(w©Żng)Įj(lu©░)Ą─ŠW(w©Żng)┐©ĪŻ└¹ė├▀@éĆ(g©©)įO(sh©©)éõį┌AWSĄ─Łh(hu©ón)Š│└’├µŠ═╠ß╣®┴╦į÷ÅŖ(qi©óng)┬ō(li©ón)ŠW(w©Żng)Ą──▄┴”Ż¼▒╚╚ńC3ĪóC4Ą─īŹ(sh©¬)└²Ż¼╦³éāĄ──│éĆ(g©©)╠žąįŠ═─▄▀_(d©ó)ĄĮ10GBĪŻūŅ├„’@Ą─╩Ū═╠═┬┴┐Ģ■╠ßĖ▀Ż¼▓óŪęĮĄĄ═┴╦ŠW(w©Żng)Įj(lu©░)ŲĮŠ∙═∙ĘĄĢr(sh©¬)čėĪó£p╔┘┴╦ČČäė ĪŻąĶę¬ÅŖ(qi©óng)š{(di©żo)Ą─╩Ū▓╗═¼Ą─ŅÉą═║═ą═╠¢Ż¼▀@éĆ(g©©)╠žąįĢ■ėą╦∙▓ŅäeŻ¼╦∙ęįį┌▀xō±Ą─Ģr(sh©¬)║“ę╗Č©ę¬ÅŖ(qi©óng)š{(di©żo)─ŃūŅ║├▀xō±ų¦│ųį÷ÅŖ(qi©óng)┬ō(li©ón)ŠW(w©Żng)╠žąįĄ─ŅÉą═Ż¼Ģ■Ą├ĄĮę╗éĆ(g©©)Ė³║├Ą─ŠW(w©Żng)Įj(lu©░)¾w“×(y©żn)ĪŻ
╗žĄĮLinuxā╚(n©©i)║╦▀@éĆ(g©©)įÆŅ}Ż¼╬ęéāüĒ┐┤┐┤ßśī”äé▓┼šäĄĮĄ─╝╝ąg(sh©┤)╠ž³c(di©Żn)Ż¼╚ń║╬└¹ė├╝╝ąg(sh©┤)╩ųČ╬Ä═ų·╬ęéā▀M(j©¼n)ąąā×(y©Łu)╗»ĪŻ╬ęéā║åå╬üĒšfėąŲ▀┤¾ĘĮ├µŻ¼Š═╩ŪCPUš{(di©żo)Č╚Ų„Īó╠ōöMā╚(n©©i)┤µĪóŠ▐ą═ĒōĪó╬─╝■ŽĄĮy(t©»ng)Īó┤µā”Ą─IOĪóŠW(w©Żng)Įj(lu©░)ĪóHypervisor ĪŻßśī”▓╗═¼Ą─ł÷Š░Ģ■ėąĖ„ĘNā×(y©Łu)╗»Ą─▀xĒŚ(xi©żng)║═▓▀┬įŻ¼╚ń╣¹▀M(j©¼n)ąą▀m«ö(d©Īng)š{(di©żo)š¹Ż¼į┌─│ĘNęŌ┴x╔Žī”╬ęéāæ¬(y©®ng)ė├Ą─ąį─▄Ģ■ėą║▄┤¾Ą─╠ß╔²ĪŻ

▒╚╚ńšf╚ń╣¹░▓čb┴╦schedtool▀@┐Ņ╣żŠ▀Ż¼▀@éĆ(g©©)╣żŠ▀┐╔ęį═©▀^GitHub╦č╦„Ž┬▌dĪŻ╩╣ė├ų«║¾┐╔ęįßśī”├┐ę╗éĆ(g©©)ųĄ▀M(j©¼n)ąą╠ž╩ŌĄ─╠Ä└ĒŻ¼╬ęį┌łDųą┴ą│÷┴╦ę╗éĆ(g©©)╠žąįŻ¼ė├BģóöĄ(sh©┤)╩╣ķLĢr(sh©¬)ķg▀\(y©┤n)ąąĄ─▀M(j©¼n)│╠Ą├ĄĮę╗éĆ(g©©)ĘŪ│Ż║├Ą─ąį─▄ā×(y©Łu)╗»Ż¼£p╔┘┴╦╔ŽŽ┬╬─Ą─ŪąōQĪŻ╚ń╣¹ÅŖ(qi©óng)š{(di©żo)īŹ(sh©¬)Ģr(sh©¬)ąįŻ¼┐╔ęįė├RģóöĄ(sh©┤)▀M(j©¼n)ąą╠žČ©Ą─ā×(y©Łu)╗»ĪŻ

ßśī”╠ōöMā╚(n©©i)┤µŻ¼īóswappinessįO(sh©©)ų├×ķ0┐╔ęįßīĘ┼│÷Ė³ČÓĄ─ā╚(n©©i)┤µĪŻ╬ęéā┐╔ęį═©▀^▀@ą®ģóöĄ(sh©┤)įO(sh©©)Č©Ż¼╩╣╬ęéāĄ─ŽĄĮy(t©»ng)Ė³▀m║Žė┌╬ęéāā╚(n©©i)┤µŽ¹║─Ą─ąĶŪ¾ĪŻ╚▒╩ĪĄ─Ģr(sh©¬)║“swappiness╩Ū┤“ķ_Ą─Ż¼▓óŪęųĄ╩Ū60Ż¼╬ęéā┐╔ęįĖ─│╔10Ė³║├Ąž╠ß╔²ąį─▄ĪŻ
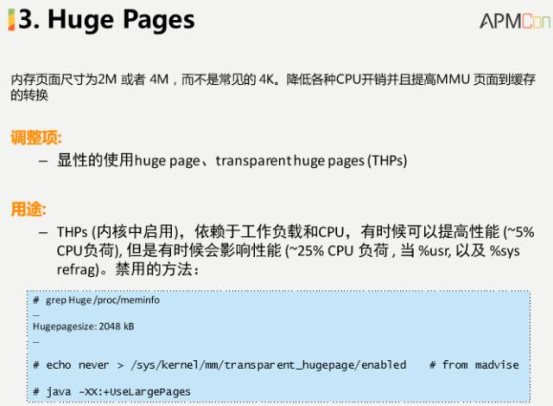
Š▐ą═Ēōę▓╩Ūā╚(n©©i)┤µįLå¢╔Žųžę¬Ą─╠žąįŻ¼│ŻęŖĄ─ā╚(n©©i)┤µ╣▄└Ē╩Ū═©▀^ā╚(n©©i)┤µ┼õų├Ą─ĘĮ╩Į▀M(j©¼n)ąą╣▄└ĒŻ¼╚▒╩ĪĄ─Ūķør╩Ū4KŻ¼─Ū├┤╚ń╣¹ėą1GBā╚(n©©i)┤µŻ¼Š═Ģ■ėą26╚fĒōĄ─╣▄└ĒĒŚ(xi©żng)Ż¼╚ń╣¹ā╚(n©©i)┤µĖ³┤¾Š═Ģ■Ė³╝ė²ŗ┤¾ĪŻ╬ęéāĮø(j©®ng)│ŻĢ■į┌▀@śė┤¾Ą─▒Ēųą▀M(j©¼n)ąą▓ķšęŻ¼╚ń╣¹öĄ(sh©┤)ō■(j©┤)┴┐ĘŪ│Ż┤¾Ż¼─│ĘN│╠Č╚╔ŽĢ■ė░Ēæ╩╣ė├Ą─ą¦┬╩ĪŻ╚▒╩ĪŪķørŽ┬į┌EC2Ą──│éĆ(g©©)īŹ(sh©¬)└²└’├µīóĒōįO(sh©©)ų├×ķ 2MŻ¼─Ńę▓┐╔ęįįO(sh©©)ų├│╔Ė³┤¾Ą─ųĄĪŻį┌▓╗═¼Ą─æ¬(y©®ng)ė├└’├µČ╝Ģ■ī”page▀M(j©¼n)ąą║▄║├Ą─įO(sh©©)ų├ĪŻ

╬─╝■ŽĄĮy(t©»ng)╩Ū║▄╠žäeĄ─æ¬(y©®ng)ė├ł÷Š░Ż¼ąĶę¬╬ęéāę²ŲūóęŌĪŻ▓╗═¼Ą─╬─╝■ŽĄĮy(t©»ng)ėą║▄ČÓ┐╔š{(di©żo)š¹Ą─ģóöĄ(sh©┤)Ż¼═©│Ż▀@ą®ā×(y©Łu)╗»Ą─ĒŚ(xi©żng)─┐Č╝ć·└@▀@ÄūéĆ(g©©)ģóöĄ(sh©┤)▀M(j©¼n)ąąŻ¼░³└©background flush earlierĪó aggressive flush laterĄ╚Ż¼▀@ą®Č╝ę└═ą╬ęéāŠ▀¾wĄ─╩╣ė├Łh(hu©ón)Š│║═ąĶŪ¾═Ļ│╔ĪŻęįdirty_background_ratio×ķ└²Ż¼╚▒╩ĪŪķørŽ┬╩Ū10Ż¼▀@└’įO(sh©©)ų├×ķ5üĒ╠ßĖ▀Ēææ¬(y©®ng)╦┘Č╚║═╠Ä└Ē─▄┴”ĪŻ

Storage I/Oų„ę¬╩Ūßśī”ēKįO(sh©©)éõ▀M(j©¼n)ąąā×(y©Łu)╗»Ą─š{(di©żo)š¹ĒŚ(xi©żng)Ż¼┤¾╝ęų¬Ą└į┌▓┘ū„ŽĄĮy(t©»ng)└’├µŻ¼Linux▓┘ū„ŽĄĮy(t©»ng)ų¦│ųŅA(y©┤)ūxĄ──▄┴”Ż¼╦³┐╔ęįŅA(y©┤)ų¬Ž┬ę╗éĆ(g©©)ę¬ūx╚ĪĄ─╬─╝■Ż¼īó╦³ūxĄĮā╚(n©©i)┤µ└’ĪŻŁh(hu©ón)Š│ūā╗»┴╦Ż¼─┐Ū░║▄ČÓæ¬(y©®ng)ė├▄ø╝■ī”▀@éĆ(g©©)╠žąį╩ŪĘŪ│Ż├¶ĖąĄ─Ż¼▀@ĘNŪķørŽ┬╬ęéā┐╔ęįī”read ahead size▀M(j©¼n)ąąę╗ą®ā×(y©Łu)╗»║═š{(di©żo)š¹Ż¼╔§ų┴┐╔ęį░č╦³Į¹ė├ĪŻ┴Ē═ŌSSD│÷¼F(xi©żn)ų«║¾Ż¼╩╣Ą├╬ęéāé„Įy(t©»ng)Ą─š{(di©żo)Č╚ĘĮĘ©«a(ch©Żn)╔·┴╦ūā╗»Ż¼▒╚╚ń╬ęéāĮø(j©®ng)│Ż▓╔ė├Ą─š{(di©żo)Č╚▓▀┬į╩ŪCFQŻ¼╦³ī” SSDŠ═▓╗╩ŪĘŪ│Żėč║├Ż¼Ė³║├Ą─ĘĮĘ©╬ęéā═Ų╦]╩╣ė├“noop” schedulerŻ¼╦∙ęį┐╔ęį═©▀^▀@śėĄ─ę╗ą®Ė─ūā╩╣Ą├╬ęéāĖ³║├ĄžŲź┼õSSD½@Ą├▓╗═¼æ¬(y©®ng)ė├ł÷Š░Ą─ąĶŪ¾ĪŻ
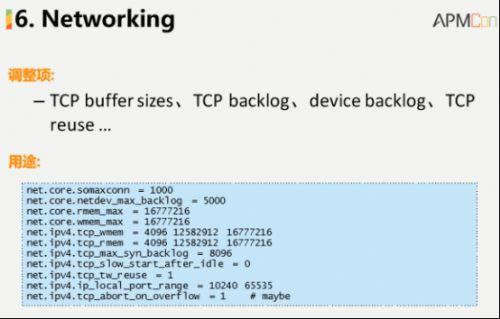
ī”ė┌ŠW(w©Żng)Įj(lu©░)Ż¼┤¾╝ęČ╝║▄ŪÕ│■Ż¼╬ęéāėą║▄ČÓĄ─ŠW(w©Żng)Įj(lu©░)ā×(y©Łu)╗»ĒŚ(xi©żng)▀M(j©¼n)ąąš{(di©żo)š¹║═įO(sh©©)ų├Ż¼▀@ą®ā×(y©Łu)╗»ĒŚ(xi©żng)ĘNŅÉ║═öĄ(sh©┤)┴┐ĘŪ│ŻČÓŻ¼Ųõųą░³║¼┴╦Ž±buffer sizesĪóbacklogĄ╚Ż¼▀@ą®ĒŚ(xi©żng)┤¾╝ę┐╔ęįßśī”Š▀¾wĄ─Įø(j©®ng)“×(y©żn)▀M(j©¼n)ąąā×(y©Łu)╗»╠Ä└ĒĪŻ

▀Ćėąę╗ĘNæ¬(y©®ng)ė├ł÷Š░Š═╩Ūį┌╠ōöM╗»Ą─Łh(hu©ón)Š│└’├µŻ¼įŲėŗ(j©¼)╦Ń└’├µĮø(j©®ng)│ŻĢ■ė÷ĄĮĄ─Ż¼ßśī”Hypervisor Ą─ā×(y©Łu)╗»ĪŻūŅų„ꬥ─ā×(y©Łu)╗»ĒŚ(xi©żng)Š═╩ŪclocksourceŻ¼░³└©Ž±hpetĪóxenĪótscĄ╚Ą╚ĪŻ
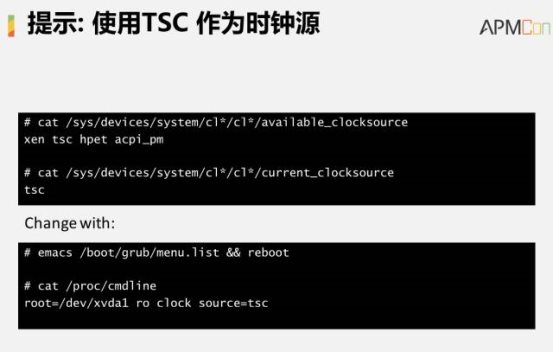
į┌╬ęéāĄ─Łh(hu©ón)Š│└’╚▒╩ĪĄ─EC2Ģr(sh©¬)ńŖį┤Č╝╩ŪXenŻ¼╚ń╣¹─Ńė├cat├³┴Ņūx╚ĪČ╝╩Ū▀@śėĄ─ĪŻ▀@└’├µėą╩▓├┤ģ^(q©▒)äe─žŻ┐║åå╬üĒšfhpet╩Ūę╗éĆ(g©©)ė▓╝■Ą─Ģr(sh©¬)ńŖį┤Ż¼╦³╠ß╣®┴╦ĘŪ│Ż║├Ą─▒O(ji©Īn)┐žŻ¼Ą½╩Ū╦³ąĶꬫa(ch©Żn)╔·ŽĄĮy(t©»ng)Ą─š{(di©żo)Č╚Ż¼ķ_õN▒╚▌^┤¾ĪŻXenĄ─▀mė├ąįĘŪ│Ż║├Ż¼╦∙ęįį┌╠ōöM╗»Łh(hu©ón)Š│└’├µ╚▒╩ĪĢ■╩╣ė├╦³ĪŻtsc╩Ū═©▀^ėŗ(j©¼)╦ŃŲ„Ą─ĘĮĘ©½@Ą├▀@śėĄ─Ģr(sh©¬)ńŖį┤Ż¼▓ó▓╗ąĶę¬ė├ŽĄĮy(t©»ng)š{(di©żo)Č╚üĒīŹ(sh©¬)¼F(xi©żn)Ż¼ų╗ąĶę¬į┌ė├æ¶┐šķgŠ═┐╔ęįĄ├ĄĮŻ¼Ą½ŽÓī”üĒšfŠ½Č╚▓╗╚ńhpetŻ¼Ą½╩Ū╦┘Č╚╔Žtsc╩ŪūŅ║├Ą─▒Ē¼F(xi©żn)ĪŻ╦∙ęį─Ń┐╔ęįćLįć░čĢr(sh©¬)ńŖį┤įO(sh©©)ų├×ķtsc▀M(j©¼n)ąąė^£yĪŻ▒╚▌^└ĒŽļĄ─ŪķørŽ┬Ż¼CPUĄ─ė├┴┐┐╔ęįĮĄĄ═30%Ż¼«ö(d©Īng)╚╗╚ń╣¹▒Ē¼F(xi©żn)▓╗║├ę▓Ģ■«a(ch©Żn)╔·Ņ~═ŌĄ─Ė▒ū„ė├ĪŻ
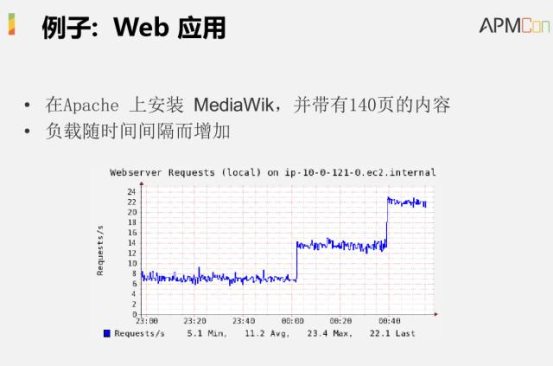
╬ęéāäé▓┼╠ߥĮ┴╦▒O(ji©Īn)£yŻ¼į┌AWSĄ─Łh(hu©ón)Š│└’├µėą║▄ČÓĘ■äš(w©┤)┐╔ęįÄ═ų·╬ęéā▀_(d©ó)│╔▀@éĆ(g©©)─┐ś╦(bi©Īo)ĪŻęį▀@éĆ(g©©)WebServer×ķ└²Ż¼į┌▀@éĆ(g©©)ł÷Š░└’├µŻ¼┐╔ęį═©▀^▒O(ji©Īn)┐ž┐┤ĄĮ▓╗═¼WebServeršłŪ¾Ą─▒Ē¼F(xi©żn)Ż¼ę▓┐╔ęį┐┤ĄĮā╚(n©©i)┤µĄ─╩╣ė├ŪķørŻ¼░³└©┤┼▒PĄ─Įy(t©»ng)ėŗ(j©¼)ŪķørĪóŠW(w©Żng)Įj(lu©░)Ą─╩╣ė├Įy(t©»ng)ėŗ(j©¼)Ą╚Ą╚Ż¼╦∙ėąĄ─▒O(ji©Īn)┐žųĖś╦(bi©Īo)Č╝╩Ū╬ęéā▀M(j©¼n)ąąā×(y©Łu)╗»Ą─ĘŪ│Żųžę¬Ą─╗∙ĄA(ch©│)Śl╝■ĪŻ

ā×(y©Łu)╗»Ģr(sh©¬)ę▓Ģ■ėąę╗ą®▓╗║├Ą─ā×(y©Łu)╗»ł÷Š░Ż¼ŽŻ═¹┤¾╝ęę²ŲūóęŌĪŻĄ┌ę╗ĘN╩Ū“┤“Ąž╩¾” ╩ĮĄ─ā×(y©Łu)╗»Ż¼▀@éĆ(g©©)╩Ū╩▓├┤śėĄ─ł÷Š░─žŻ┐Š═╩ŪļSÖC(j©®)Ą─š{(di©żo)š¹ģóöĄ(sh©┤)Ż¼─ŃćLįćų°╗“š▀šf▓┬£yąįĄ─ī”ģóöĄ(sh©┤)▀M(j©¼n)ąąš{(di©żo)š¹Ż¼▓óø]ėąų▒ė^Ą─▀ē▌ŗĻP(gu©Īn)ŽĄūC├„╦³Ģ■ėąė░ĒæŻ¼─Ńų╗╩Ūį┌┘Ć▓®ĪŻ╚ń╣¹¼F(xi©żn)Ž¾Ž¹╩¦┴╦─Ń┐╔─▄╝┘įO(sh©©)Ą─šJ(r©©n)×ķ▀@ĘNĘĮ╩Į╚ĪĄ├┴╦ą¦╣¹Ż¼▀@ĘNĘĮ╩ĮŲõīŹ(sh©¬)ėą║▄┤¾Ą─┼╝╚╗ąįŻ¼▓ó▓╗─▄║▄║├Ą─ĮŌøQå¢Ņ}Ż¼╦∙ęįę¬▒M┴┐▒▄├ŌĪŻ┴Ēę╗ĘN╩Ū“Įų¤¶”╩ĮĄ─ā×(y©Łu)╗»Ż¼ų╗┐┤ĄĮ┴╦č█Ū░ę╗³c(di©Żn)³c(di©Żn)Ą─ŪķørŻ¼Š═╩Ū▀xō±ūį╝║╩ņŽżĄ─╣żŠ▀╗“š▀ļS▒ŃÅ─╗ź┬ō(li©ón)ŠW(w©Żng)╔ŽšęĄĮę╗éĆ(g©©)╣żŠ▀Ż¼╔§ų┴ļSÖC(j©®)▀xō±ę╗┐Ņ╣żŠ▀Š═ū„×ķ─Ńģó┐╝Ą─ę└ō■(j©┤)Ż¼▀@ą®ĘĮĘ©Č╝ėą║▄┤¾Ą─▒ūČ╦ĪŻ

ę╗éĆ(g©©)▒╚▌^ėąą¦Ą─ĘĮĘ©╬ęéāÅŖ(qi©óng)š{(di©żo)╩Ū╗∙ė┌ė^▓ņŻ¼╩╣ė├ę╗ą®Įy(t©»ng)ėŗ(j©¼)╣żŠ▀ė^▓ņŽĄĮy(t©»ng)Ą─ąį─▄║═┘Yį┤Ą─╩╣ė├ŪķørŻ¼ė├öĄ(sh©┤)ō■(j©┤)üĒūC├„─ŃĄ─ā×(y©Łu)╗»╩ŪĖ▀ą¦Ą─ĪŻÅ─╩╣ė├ĘĮ╩ĮüĒ┐┤Š═╩Ūī”ė▓╝■║═▄ø╝■Ą─ĮM╝■Ż¼ųę╗▀M(j©¼n)ąąĘųĮŌŻ¼čąŠ┐├┐éĆ(g©©)ĮM╝■┐╔ęįš{(di©żo)š¹Ą─ģóöĄ(sh©┤)Ż¼▓óŪęėąę╗éĆ(g©©)├„┤_Ą─Īó┴┐╗»Ą─ŅA(y©┤)Ų┌Ż¼═©▀^š{(di©żo)š¹ģóöĄ(sh©┤)┐┤─▄▓╗─▄ØMūŃŅA(y©┤)Ų┌üĒ▀_(d©ó)ĄĮā×(y©Łu)╗»─┐Ą─ĪŻ

▀@└’├µ╠žäeÅŖ(qi©óng)š{(di©żo)Ą─ę╗éĆ(g©©)ĘĮĘ©Ż¼Įąū÷USEŻ¼Š═╩Ū└¹ė├┬╩Īó’¢║═Č╚║═Õe(cu©░)š`öĄ(sh©┤)ĪŻ▀@éĆ(g©©)ĘĮĘ©į┌ę╗▒ŠĢ°└’├µųvĄ─ĘŪ│Żįö╝Ü(x©¼)Ż¼Įąū÷ĪČSystems PerformanceĪĘŻ¼╦³Š═ÅŖ(qi©óng)š{(di©żo)┴╦ė├└¹ė├┬╩Īó’¢║═Č╚ĪóÕe(cu©░)š`öĄ(sh©┤)▀@╚²éĆ(g©©)ŠSČ╚Ä═ų·╬ęéā▀M(j©¼n)ąąš{(di©żo)š¹ā×(y©Łu)╗»Ż¼į┌▀@▒ŠĢ°└’ėąĘŪ│Żįö╝Ü(x©¼)Ą─├Ķ╩÷ĪŻ

│²┴╦äé▓┼šäĄĮĄ─ĘĮĘ©ų«═Ō▀Ćėąę╗ą®ĄžĘĮąĶę¬┤¾╝ę┐╝æ]Ż║
•į┌įŲėŗ(j©¼)╦ŃĄ─Łh(hu©ón)Š│└’├µŻ¼ėąĄ─Ģr(sh©¬)║“Å═(f©┤)ļsĄ─å¢Ņ}▓óø]ėą├„┤_Ą─┤░ĖŻ¼╝┤╩╣╩Ū─Ńū÷┴╦ćLįć║═š{(di©żo)š¹ę▓ø]ėą┤░ĖŻ¼ėą┐╔─▄╩Ū─ŃąĶę¬ōQę╗éĆ(g©©)īŹ(sh©¬)└²┴╦Ż¼▒╚╚ńōQę╗éĆ(g©©)Ė³┤¾Ą─ą═╠¢╗“š▀Ė³ÅŖ(qi©óng)ä┼Ą─īŹ(sh©¬)└²▓┼─▄Ä═ų·ĮŌøQå¢Ņ}ĪŻ
•ėąĢr(sh©¬)║“Ęų╬÷ų«║¾┤_šJ(r©©n)┼cīŹ(sh©¬)└²ėąĻP(gu©Īn)Ż¼Ą½╩Ū┤¾ČÓöĄ(sh©┤)┐╔─▄┼cæ¬(y©®ng)ė├ėąĻP(gu©Īn)Ż¼▀@Å─Įy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)üĒ┐┤Ę¹║Ž80/20įŁätŻ¼ę▓Š═╩Ūšf80%┐╔─▄ąį┼cæ¬(y©®ng)ė├ėąĻP(gu©Īn)Ż¼ų╗ėą20%╩ŪĖ·╗∙ĄA(ch©│)╝▄śŗ(g©░u)▓┘ū„ŽĄĮy(t©»ng)ėąĻP(gu©Īn)Ą─ĪŻ║åå╬üĒšf80%╩ŪĖ·æ¬(y©®ng)ė├│╠ą“▒Š╔ĒėąĻP(gu©Īn)Ą─Ż¼═©▀^│╠ą“Ą─ā×(y©Łu)╗»║═ųžśŗ(g©░u)Š═┐╔ęįØMūŃ╗“š▀ĮŌøQæ¬(y©®ng)ė├å¢Ņ}Ż¼ų╗ėą20%Ą─ł÷Š░└’├µ─ŃąĶę¬ī”▓┘ū„ŽĄĮy(t©»ng)╗∙ĄA(ch©│)╝▄śŗ(g©░u)ā×(y©Łu)╗»Ż¼▓┼┐╔ęįĮŌøQŻ¼┤¾╝ęę╗Č©ę¬ėøĄ├Ż¼▓╗ę¬╔ŽüĒŠ═ćLįćī”▓┘ū„ŽĄĮy(t©»ng)▀M(j©¼n)ąą╠½ČÓĄ─ā×(y©Łu)╗»Ż¼┐╔─▄ė¹╦┘ät▓╗▀_(d©ó)ĪŻ
•ėąą®ł÷Š░Ģ■ėąą®ęŌ═ŌŻ¼▒╚╚ńšfčė▀t«É│ŻĄ─ł÷Š░Ż¼20%╩Ūė╔┤·┤aę²ŲĄ─Ż¼Ė³ČÓĄ─ę“╦ž╩Ūė╔īŹ(sh©¬)└²Ą─ŅÉą═ĪóŠW(w©Żng)Įj(lu©░)Ą─▀xō±Īó└¼╗°╗ž╩šĄ╚«a(ch©Żn)╔·Ą─ĪŻ
į┌Ęų╬÷ĘĮĘ©╔ŽŻ¼ī”ė┌žō(f©┤)▌dĄ─Ęų╬÷Ż¼Į©ūh╩ŪūįĒöŽ“Ž┬Ż¼Å─æ¬(y©®ng)ė├Ą─žō(f©┤)▌dų°╩ųŻ¼╚╗║¾ĘųĮŌšłŪ¾Ģr(sh©¬)ķgĪŻī”┘Yį┤Ą─Ęų╬÷Į©ūhūįŽ┬Č°╔ŽŻ¼Å─┘Yį┤Ą─ąį─▄ķ_╩╝ų°╩ųŻ¼╚╗║¾╩Ū╣żū„žō(f©┤)▌dŻ¼┤¾╝ęį┌Ęų╬÷Ą─Ģr(sh©¬)║“┐╔ęįņ`╗ŅšŲ╬šĪŻ
ī”ė┌ąį─▄╣żŠ▀Ż¼│²┴╦įŲėŗ(j©¼)╦ŃŲĮ┼_╠ß╣®Ą─ė^▓ņ╣żŠ▀ų«═Ō▀Ćėąę╗ą®ŽĄĮy(t©»ng)Ą─╣żŠ▀Ż¼┐╔ęįī”▓┘ū„ŽĄĮy(t©»ng)Ą─║╦ą─▀M(j©¼n)ąą║▄║├Ą─Įy(t©»ng)ėŗ(j©¼)Ż¼▀@└’╬ęéāĮķĮB╦─┤¾ĘĮ├µĄ─╣żŠ▀Įo┤¾╝ęģó┐╝ĪŻ
•Statistical ╣żŠ▀╝┤Įy(t©»ng)ėŗ(j©¼)╣żŠ▀Ż¼░³└©vmstatĪópidstatĪósarĄ╚Ą╚ĪŻąĶę¬ÅŖ(qi©óng)š{(di©żo)Ą─╩Ū▀@ą®╣żŠ▀ø]ėą░▓čbĄĮAWS EC2Ą─╚▒╩ĪŁh(hu©ón)Š│└’├µŻ¼ąĶę¬╩ų╣ż░▓čbŻ¼░▓čbų«║¾─Ń┐╔ęį┐┤ĄĮī”ŠW(w©Żng)Įj(lu©░)ĀŅørĘŪ│Żįö╝Ü(x©¼)Ą─Įy(t©»ng)ėŗ(j©¼)ĪŻ
•profiling ╣żŠ▀Ż¼Š═╩Ūī”CPUČ茯▀M(j©¼n)ąąĖ·█ÖŻ¼ĮŌßīCPUĄ─╩╣ė├ŪķørŻ¼ī”ā╚(n©©i)┤µī”Ž¾▀M(j©¼n)ąąĖ·█ÖŻ¼ĮŌßīā╚(n©©i)┤µĄ─╩╣ė├ŪķørŻ¼«a(ch©Żn)╔·Ą─š{(di©żo)ā×(y©Łu)Š═╩Ūī”¤ß┤·┤aĄ─┬ĘÅĮ▀M(j©¼n)ąąš{(di©żo)š¹║═┼õų├Ż¼▒╚╚ń¤ß┤·┤aĄ─å¢Ņ}Ż¼╚ń╣¹Č©╬╗ęį║¾┐╔─▄╩Ūšµš²Ą─Ų┐ŅiŻ¼─Ń┐╔ęįŠ█Į╣į┌▀@³c(di©Żn)ĮŌøQūŅĮKūŅĖ∙▒ŠĄ─å¢Ņ}ĪŻ┴Ē═Ōī”ŅlĘ▒Ą─ī”Ž¾Ą─Ęų┼õŻ¼ė╚Ųõ╩Ūā╚(n©©i)┤µ╩╣ė├╔ŽŻ¼ę▓┐╔ęį└¹ė├▀@ą®ĘĮĘ©║═╣żŠ▀Ä═╬ęéāĮŌøQ╦³ĪŻßśī”▀@éĆ(g©©)│╠ą“ėą║▄ČÓ▓╗═¼Ą─profiling╣żŠ▀Ż¼▀@└’├µ═Ų╦]Ą─Š═╩ŪLightweight Java Profiler Ą─╣żŠ▀ĪŻ
LJP ╩Ūę╗éĆ(g©©)ķ_į┤Ą─ĒŚ(xi©żng)─┐Ż¼ų„ę¬ßśī”javaĪŻā×(y©Łu)³c(di©Żn)ėąā╔³c(di©Żn)Ż¼Ą┌ę╗Š═╩ŪŠ½Č╚ĘŪ│ŻĖ▀Ż¼Ą┌Č■Š═╩Ūų¦│ų╗赳DĄ─▌ö│÷ĪŻ╗赳D╩Ūę╗éĆ(g©©)ĘŪ│Ż║├═µĄ─¢|╬„Ż¼ę▓ĘŪ│Żų▒ė^ĪŻŽ┬├µ╩Ūę╗éĆ(g©©)╗赳DĄ─└²ūėŻ¼ŲõīŹ(sh©¬)ĘŪ│Ż║åå╬Ż¼Y▌S╩ŪČ茯Ą─ŪķørŻ¼X▌S╩Ū╚ĪśėŅlČ╚Ą─ŪķørĪŻ═©▀^▀@éĆ(g©©)łD╝╚╩╣─Ńø]ėą╠½ČÓĄ─Ģr(sh©¬)ķg╗“š▀╚▒╔┘Įø(j©®ng)“×(y©żn)ę▓┐╔ęįÄ═ų·─ŃČ©╬╗ĄĮę╗éĆ(g©©)ĘĮŽ“Ż¼Å─Č°ā×(y©Łu)╗»║═ĮŌøQå¢Ņ}Ż¼╦∙ęį╗赳D╩Ū▒╚▌^═Ų╦]Ą─ĘĮĘ©ĪŻŽĄĮy(t©»ng)Ą─profiling╩Ūę╗éĆ(g©©)perfĄ─╣żŠ▀Ż¼perfę▓┐╔ęį╔·│╔CPUĄ─╗赳DŻ¼╗赳D▀@éĆ(g©©)╣żŠ▀ę▓╩Ūķ_į┤ĒŚ(xi©żng)─┐ĪŻ
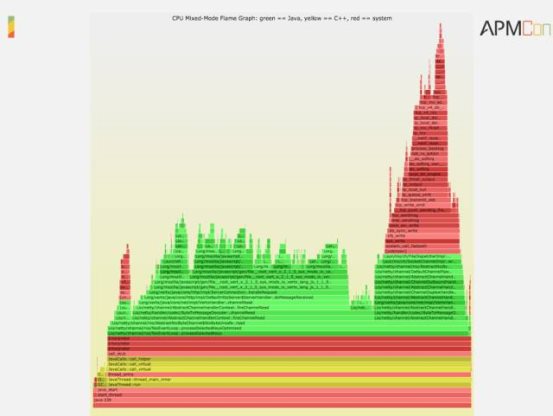
•TracingĄ─╣żŠ▀ĘŪ│ŻČÓŻ¼░³└©ftraceĪóperf_eventsĄ╚Ą╚Ż¼▓╗Įo┤¾╝ę╠žäeÅŖ(qi©óng)š{(di©żo)┴╦ĪŻąĶę¬Įo┤¾╝ęÅŖ(qi©óng)š{(di©żo)Ą─Š═╩ŪftraceŻ¼¼F(xi©żn)į┌ęčĮø(j©®ng)╩ŪLinuxĄ─ĮM│╔▓┐Ęų┴╦Ż¼╚ń╣¹─Ń┤“ķ_┤·┤aĄ─įÆ┐╔ęįį┌įŁ┤·┤a«ö(d©Īng)ųą┐┤ĄĮĪŻiosnoop╩Ūę╗éĆ(g©©)ķ_į┤ĒŚ(xi©żng)─┐Ż¼┤¾╝ęė├▀@éĆ(g©©)├¹ūų┐╔ęįŽ┬▌dĄĮŻ¼Ą½╩ŪąĶę¬─ŃŠÄūgę╗Ž┬Ż¼ąĪąĪĄ─╣żū„▓ó▓╗Å═(f©┤)ļsĪŻČ°Ūę╬ęĄ─Įø(j©®ng)“×(y©żn)üĒ┐┤Ż¼Į^┤¾ČÓöĄ(sh©┤)LinuxŁh(hu©ón)Š│└’├µę└┘ćÄņ▓ó▓╗Å═(f©┤)ļsŻ¼╣żū„┴┐ąUąĪĄ─ĪŻ
•Hardware ėŗ(j©¼)öĄ(sh©┤)Ų„ĪŻ▒╚▌^╠žäeę╗³c(di©Żn)Ą─Š═╩ŪMSRŻ¼Š═╩Ūė▓╝■Ą─ėŗ(j©¼)öĄ(sh©┤)Ų„Ż¼═©▀^▀@éĆ(g©©)ėŗ(j©¼)öĄ(sh©┤)Ų„╠ß╣®┴╦║▄ČÓ╗∙▒ŠĄ─ą┼ŽóŻ¼▓╗═¼Ą─ą═╠¢Ģ■ėą▓ŅäeĪŻį┌┤¾▓┐ĘųAWS EC2Ą─īŹ(sh©¬)└²ųąČ╝ęčĮø(j©®ng)ų¦│ųMSRĄ─╠ž³c(di©Żn)┴╦Ż¼└¹ė├▀@éĆ(g©©)╠ž³c(di©Żn)Š═┐╔ęį═Ļ│╔║▄ČÓī”CPUĄ═╝ēäeĄ─▒O(ji©Īn)┐ž▓┘ū„ĪŻŲõīŹ(sh©¬)MSR╣żŠ▀ę▓╩Ūę╗éĆ(g©©)GitHubĄ─╣żŠ▀Ż¼╦³─▄ū÷║▄ČÓėąęŌ╦╝Ą─╩┬ŪķŻ¼▒╚╚ńšfī”CPUĄ─ą═╠¢ĪóŅl┬╩ĪóĀŅæB(t©żi)Ą╚Ą╚▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ą─½@╚ĪŻ¼╚╗║¾═©▀^▀@ą®öĄ(sh©┤)ō■(j©┤)Č©╬╗─Ń╦∙ąĶꬥ─ę╗ą®ą┼ŽóŻ¼Š═┐╔ęįšęĄĮ─ŃąĶ꬚{(di©żo)ā×(y©Łu)Ą─ÄūéĆ(g©©)³c(di©Żn)ĪŻ
Üw╝{ŲüĒĮ±╠ņųv┴╦║▄ČÓ╣żŠ▀Ż¼ųv┴╦ę╗ą®ąĶę¬ūóęŌĄ─įŁätĪŻ╬ęŽļ░čūŅ║¾▀@╚²³c(di©Żn)ū„×ķ┐éĮY(ji©”)ĘųŽĒĮo┤¾╝ęĄ─Įø(j©®ng)“×(y©żn)ĪŻ
•Ą┌ę╗Ż¼į┌įŲėŗ(j©¼)╦ŃŁh(hu©ón)Š│└’├µŻ¼ė╔ė┌╬ęéā├µī”Ą─Łh(hu©ón)Š│▓╗═¼ė┌╬’└ĒŁh(hu©ón)Š│Ż¼ėąĖ³ČÓĄ─╠ōöM┘Yį┤Ż¼ėąĖ³ČÓĄ─▀xō±ĒŚ(xi©żng)ĪŻī”ė┌ā×(y©Łu)╗»Ą─ł÷Š░üĒšfŻ¼▀xō±ę╗éĆ(g©©)║Ž▀mĄ─īŹ(sh©¬)└²Š═Ą╚ė┌ąį─▄ā×(y©Łu)╗»Ż¼┤¾╝ęŪ¦╚f▓╗ꬹĪŪŲ▀@éĆ(g©©)ĮY(ji©”)šōŻ¼ę▓╩Ū║▄ČÓĄ─Įø(j©®ng)“×(y©żn)ōQüĒ┴╦ĪŻ
•Ą┌Č■Ż¼░┤šš80/20įŁätŻ¼į┌ąĶꬥ─Ģr(sh©¬)║“─Ń┐╔ęį╩╣ė├Linuxā╚(n©©i)║╦Īóąį─▄ā×(y©Łu)╗»╗“š▀Įy(t©»ng)ėŗ(j©¼)Ą─ĘĮĘ©▀M(j©¼n)ąąė^▓ņŻ¼▓óŪę╗∙ė┌öĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)¼F(xi©żn)ī”║╦ą─Ą─š{(di©żo)ā×(y©Łu)ĪŻūŅųžę¬Ą─╩Ū╦∙ėąĄ─ā×(y©Łu)╗»Č╝╩Ū╗∙ė┌▒O(ji©Īn)£yĄ─ĮY(ji©”)╣¹Ż¼Č╝╩Ūė╔öĄ(sh©┤)ō■(j©┤)“ī(q©▒)äėĄ─Ż¼╦∙ęįŪ¦╚f▓╗ę¬║÷┬įĄ¶ĪŻ
•╩╣ė├─Ń╩ų╔Ž╦∙ėąĄ─╣żŠ▀Ż¼░³└©įŲėŗ(j©¼)╦ŃŲĮ┼_╔ŽĄ─╣żŠ▀Īó▓┘ū„ŽĄĮy(t©»ng)ūįĦĄ─╣żŠ▀ęį╝░╬ęéā┐╔ęįŽ┬▌dĄ─╣żŠ▀üĒ½@Ą├─ŃĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ė├öĄ(sh©┤)ō■(j©┤)üĒšfĘ■─Ń▀xō±──ę╗éĆ(g©©)ā×(y©Łu)╗»Ą─ĘĮŽ“ĪŻ
