

į┌äéäéĮY(ji©”)╩°Ą─ć·ŲÕ╚╦ÖCĄ┌Č■ł÷▒╚┘ÉųąŻ¼AlphaGoł╠(zh©¬)║┌į┘Ž┬ę╗│ŪŻ¼įŁüĒī”└Ņ╩└╩»▒¦ėą║▄┤¾Ų┌═¹Ą─ć·ŲÕĮń╚╦╩┐ą┼ą─╩▄ĄĮųžäō(chu©żng)Ż¼═¼śėū„×ķ┬ÜśI(y©©)Š┼Č╬Ą─▀x╩ųŻ¼┐┬ØŹ╔§ų┴į┌Ą┌Č■ł÷▒╚┘É╬┤ĮY(ji©”)╩°ĢrŠ═▒Ē╩ŠŻ¼¼F(xi©żn)į┌ų╗ŽŻ═¹└Ņ╩└╩»┌Aę╗ł÷░Ō╗ž├µūėŠ═║├ĪŻ─Ū├┤å¢Ņ}üĒ┴╦Ż¼AlphaGoį┘Ž┬ę╗│ŪŻ¼▀@╩Ūʱ┤·▒Ēšµš²Ą─ųŪ─▄ęčĮø(j©®ng)šQ╔·Ż┐

AlphaGoŻ║╩Ū║┌┐Ų╝╝Ż¼Ą½▓╗╔±├ž
┐╔ęį▀@śėšfŻ¼AlphaGo┤·▒Ē┴╦«ö(d©Īng)Į±ūŅŽ╚▀MĄ─╚╦╣żųŪ─▄Ż¼╦³╗∙ė┌╔ŅČ╚īW(xu©”)┴Ģ(x©¬)╦ŃĘ©Ż¼ų╗─▄─ŻöM╚╦ŅÉ╔±Įø(j©®ng)į¬Ą─ąą×ķ─Ż╩ĮŻ¼Å─ę╗ĘN▌ö╚ļĄ├ĄĮę╗ĘN▌ö│÷ĮY(ji©”)╣¹ĪŻļm╚╗▀@╩Ūę╗ĘN║┌┐Ų╝╝Ż¼Ą½╩Ū▓óø]ėą╩▓├┤╔±├žĄ─¢|╬„į┌└’├µĪŻ
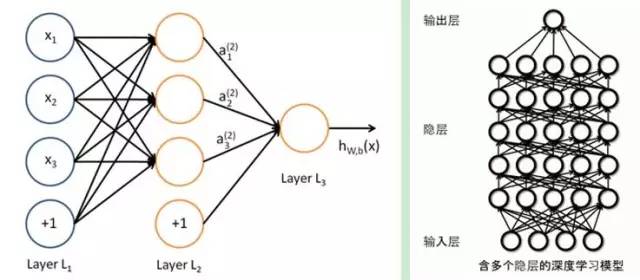
╔ŽłD╩Ū╔ŅČ╚īW(xu©”)┴Ģ(x©¬)Ą─╗∙▒Š─Żą═Ż¼Š═╩Ū─ŻöM╚╦Ą─╔±Įø(j©®ng)į¬▌S═╗Į©┴ó▀^│╠ĪŻ«ö(d©Īng)Ū░Ą─å¢Ņ}╩Ū╔ŅČ╚īW(xu©”)┴Ģ(x©¬)▄ø╝■─ŻöM╔±Įø(j©®ng)į¬Ż¼ą¦┬╩ĘŪ│Ż▓ŅĪŻ│²ĘŪėąæøūĶŲ„▀@ĘN═╗ŲŲąį╝╝ąg(sh©┤)Ż¼═Ļ╚½Ą─ųžśŗ(g©░u)ėŗ╦ŃÖC╝╝ąg(sh©┤)╝▄śŗ(g©░u)ĪŻ▀@ĘN╝╝ąg(sh©┤)ę¬Ū¾ę╗éĆå╬į¬─▄┼cöĄ(sh©┤)╩«╚féĆŲõ╦¹å╬į¬Į©┴ó╬’└Ē▀BĮėļŖ┬ĘŻ¼▓óŪę─▄▓╗öÓĖ³ą┬ĪŻŽļŽ¾Ž┬╚ń╣¹ėą─ŻöMę╗ā|éĆ╔±Įø(j©®ng)į¬ĪŻ├┐éĆ╔±Įø(j©®ng)į¬─ŻöM100╚féĆ▀BĮėĪŻŠ═╩Ū100╚fā|ŚlŠĆ┬ĘĪŻ╚╦─Xėą800ā|éĆ╔±Įø(j©®ng)į¬ĪŻ─▄▀_ĄĮ╚╦ŅÉę╗śėėŗ╦Ń─▄┴”Ą─╔ŅČ╚īW(xu©”)┴Ģ(x©¬)ÖCŲ„ę¬─▄«a(ch©Żn)╔·8╚fā|ŚlŠĆ┬ĘĪŻGOOGLEĄ─DEEP MINDę¬Ųźö│╚╦─XĄ─┼ąöÓ─▄┴”Ż¼┐╔─▄▒│║¾ąĶę¬öĄ(sh©┤)╚fŅwĖ▀Č╚╝»│╔Ą─ėøæøå╬į¬Ą─│¼╝ēļŖ─X╝»╚║üĒų¦│ųĄ─ĪŻ╚ń╣¹ėąę╗╠ņ▀@ĘN╝╝ąg(sh©┤)Ą├ĄĮŲš╝░Ż¼─Ū├┤ėŗ╦ŃÖCĢ■ĄĮ▀_╚╦ę╗śėĖ▀╦┘ūRäełDŽ±║═ęĢŅlĄ╚╣”─▄ĪŻ«ö(d©Īng)╚╗Ż¼ALPHAGO╩ŪųŪ─▄Ą─ĪŻę“×ķ╦³─▄─ŻöM╚╦─XĄ─▓┐Ęų╣”─▄Ż¼īŹ¼F(xi©żn)ę╗ĘNŅÉ╦Ų╚╦─X─Ż╩Į▀\╦Ń▓┐ĘųĄ─╣”─▄Ż¼ę▓┐╔─▄─ŻĘ┬╚╦ŅÉĄ─ąą×ķ╬®├Ņ╬®ążŻ¼Ą½╩Ū╚ń╣¹─Ńę¬╩Ūå¢└’├µ▀@└’├µĢ■▓╗╩Ū«a(ch©Żn)╔·ęŌūRĪŻ┤░Ė╩ŪĮ^ī”ø]ėąĪŻ
ALPHAgo▓╗┐╔─▄«a(ch©Żn)╔·╚╬║╬ūį╬ęęŌūRĪŻ╚╬║╬╚╦╣żųŪ─▄▀BęŌūRĄ─▀ģČ╝š┤▓╗╔ŽĪŻīŹļH╔Žęčų¬╝╝ąg(sh©┤)ųąŻ¼│²┴╦Ė·├├ūėįņ╚╦Ż¼«a(ch©Żn)╬’─▄«a(ch©Żn)╔·ęŌūRų«═ŌĪŻ▀Ćø]ėą╚╬║╬┬ĘÅĮ┐╔ęį«a(ch©Żn)╔·ėąęŌūRĄ─«a(ch©Żn)ŲĘĪŻ
╚╦Ą─┤¾─XĘųā╔éĆ▓┐ĘųĪŻę╗▓┐ĘųŻ©┤¾─XŲż┘|(zh©¼)Ż®žōž¤(z©”)«a(ch©Żn)╔·ęŌūRĪŻę╗▓┐Ęųžōž¤(z©”)ėøæøĪó▀\╦ŃĪŻDEEP MIND▀@ĘN╔ŅČ╚īW(xu©”)┴Ģ(x©¬)╦ŃĘ©─ŻöMĄ─╩Ū║¾š▀ĪŻĄ½ī”ė┌Ū░š▀Ż¼╬ęéā?n©©i)╦ŅÉ▀Ćę╗¤o╦∙ų¬Ż¼▀B└ĒšōĘĮŽ“Č╝ø]ėąŻ¼Ė³▓╗꬚f─ŻöM┴╦ĪŻ
AlphaGo└¹ė├ā╔éĆ┤¾─X┌A┴╦└Ņ╩└╩»
AlphaGo╩Ū═©▀^ā╔éĆ▓╗═¼╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)“┤¾─X”║Žū„üĒĖ─▀MŽ┬ŲÕĪŻ▀@ą®┤¾─X╩ŪČÓīė╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)Ė·─Ūą®GooglełDŲ¼╦č╦„ę²ŪµūRäełDŲ¼į┌ĮY(ji©”)śŗ(g©░u)╔Ž╩ŪŽÓ╦ŲĄ─ĪŻ╦³éāÅ─ČÓīėåó░l(f©Ī)╩ĮČ■ŠS▀^×VŲ„ķ_╩╝Ż¼╚ź╠Ä└Ēć·ŲÕŲÕ▒PĄ─Č©╬╗Ż¼Š═Ž±łDŲ¼ĘųŅÉŲ„ŠW(w©Żng)Įj(lu©░)╠Ä└ĒłDŲ¼ę╗śėĪŻĮø(j©®ng)▀^▀^×VŻ¼13 éĆ═Ļ╚½▀BĮėĄ─╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)īė«a(ch©Żn)╔·ī”╦³éā┐┤ĄĮĄ─Šų├µ┼ąöÓĪŻ▀@ą®īė─▄ē“ū÷ĘųŅÉ║═▀ē▌ŗ═Ų└ĒĪŻ

▀@ą®ŠW(w©Żng)Įj(lu©░)═©▀^Ę┤Å═(f©┤)ė¢(x©┤n)ŠÜüĒÖz▓ķĮY(ji©”)╣¹Ż¼į┘╚źąŻī”š{(di©żo)š¹ģóöĄ(sh©┤)Ż¼╚źūīŽ┬┤╬ł╠(zh©¬)ąąĖ³║├ĪŻ▀@éĆ╠Ä└ĒŲ„ėą┤¾┴┐Ą─ļSÖCąįį¬╦žŻ¼╦∙ęį╬ęéā╩Ū▓╗┐╔─▄Š½┤_ų¬Ą└ŠW(w©Żng)Įj(lu©░)╩Ū╚ń║╬“╦╝┐╝”Ą─Ż¼Ą½Ė³ČÓĄ─ė¢(x©┤n)ŠÜ║¾─▄ūī╦³▀M╗»ĄĮĖ³║├ĪŻ
Ą┌ę╗┤¾─X: ┬õūė▀xō±Ų„ Ż©Move Picker)
AlphaGoĄ─Ą┌ę╗éĆ╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)┤¾─X╩Ū“▒O(ji©Īn)ČĮīW(xu©”)┴Ģ(x©¬)Ą─▓▀┬įŠW(w©Żng)Įj(lu©░)(Policy Network)” Ż¼ė^▓ņŲÕ▒P▓╝ŠųŲ¾łDšęĄĮūŅ╝čĄ─Ž┬ę╗▓ĮĪŻ╩┬īŹ╔ŽŻ¼╦³ŅA(y©┤)£y├┐ę╗éĆ║ŽĘ©Ž┬ę╗▓ĮĄ─ūŅ╝čĖ┼┬╩Ż¼─Ū├┤ūŅŪ░├µ▓┬£yĄ─Š═╩Ū─ŪéĆĖ┼┬╩ūŅĖ▀Ą─ĪŻ─Ń┐╔ęį└ĒĮŌ│╔“┬õūė▀xō±Ų„”ĪŻ

┬õūė▀xō±Ų„╩Ūį§├┤┐┤ĄĮŲÕ▒PĄ─Ż┐öĄ(sh©┤)ūų▒Ē╩ŠūŅÅŖ╚╦ŅÉ▀x╩ųĢ■Ž┬į┌──ą®ĄžĘĮĄ─┐╔─▄ĪŻ
łFĻĀ═©▀^į┌KGSŻ©ŠW(w©Żng)Įj(lu©░)ć·ŲÕī”æ(zh©żn)ŲĮ┼_Ż®╔ŽūŅÅŖ╚╦ŅÉī”╩ųŻ¼░┘╚f╝ēĄ─ī”▐─┬õūė╚źė¢(x©┤n)ŠÜ┤¾─XĪŻ▀@Š═╩ŪAlphaGoūŅŽ±╚╦Ą─ĄžĘĮŻ¼─┐ś╦(bi©Īo)╩Ū╚źīW(xu©”)┴Ģ(x©¬)─Ūą®Ēö╝ŌĖ▀╩ųĄ─├Ņ╩ųĪŻ▀@éĆ▓╗╩Ū×ķ┴╦╚źŽ┬┌AŻ¼Č°╩Ū╚źšęę╗éĆĖ·╚╦ŅÉĖ▀╩ų═¼śėĄ─Ž┬ę╗▓Į┬õūėĪŻAlphaGo┬õūė▀xō±Ų„─▄š²┤_Ę¹║Ž57%Ą─╚╦ŅÉĖ▀╩ųĪŻŻ©▓╗Ę¹║ŽĄ─▓╗╩ŪęŌ╬Čų°Õeš`Ż¼ėą┐╔─▄╚╦ŅÉūį╝║ĘĖĄ─╩¦š`Ż®
Ė³ÅŖĄ─┬õūė▀xō±Ų„
AlphaGoŽĄĮy(t©»ng)╩┬īŹ╔ŽąĶę¬ā╔éĆŅ~═Ō┬õūė▀xō±Ų„Ą─┤¾─XĪŻę╗éĆ╩Ū“ÅŖ╗»īW(xu©”)┴Ģ(x©¬)Ą─▓▀┬įŠW(w©Żng)Įj(lu©░)Ż©Policy NetworkŻ®”Ż¼═©▀^░┘╚f╝ēŅ~═ŌĄ──ŻöMŠųüĒ═Ļ│╔ĪŻ─Ń┐╔ęįĘQų«×ķĖ³ÅŖĄ─ĪŻ▒╚Ų╗∙▒ŠĄ─ė¢(x©┤n)ŠÜŻ¼ų╗╩ŪĮ╠ŠW(w©Żng)Įj(lu©░)╚ź─ŻĘ┬å╬ę╗╚╦ŅÉĄ─┬õūėŻ¼Ė▀╝ēĄ─ė¢(x©┤n)ŠÜĢ■┼c├┐ę╗éĆ─ŻöMŲÕŠųŽ┬ĄĮĄūŻ¼Į╠ŠW(w©Żng)Įj(lu©░)ūŅ┐╔─▄┌AĄ─Ž┬ę╗╩ųĪŻSliverłFĻĀ═©▀^Ė³ÅŖĄ─┬õūė▀xō±Ų„┐éĮY(ji©”)┴╦░┘╚f╝ēė¢(x©┤n)ŠÜŲÕŠųŻ¼▒╚╦¹éāų«Ū░░µ▒ŠėųĄ³┤·┴╦▓╗╔┘ĪŻ
å╬å╬ė├▀@ĘN┬õūė▀xō±Ų„Š═ęčĮø(j©®ng)╩ŪÅŖ┤¾Ą─ī”╩ų┴╦Ż¼┐╔ęįĄĮśI(y©©)ėÓŲÕ╩ųĄ─╦«ŲĮŻ¼╗“š▀šfĖ·ų«Ū░ūŅÅŖĄ─ć·ŲÕAIµŪ├└ĪŻ▀@└’ųž³c╩Ū▀@ĘN┬õūė▀xō±Ų„▓╗Ģ■╚ź“ūx”ĪŻ╦³Š═╩Ū║åå╬īÅęĢÅ─å╬ę╗ŲÕ▒P╬╗ų├Ż¼į┘╠ß│÷Å──ŪéĆ╬╗ų├Ęų╬÷│÷üĒĄ─┬õūėĪŻ╦³▓╗Ģ■╚ź─ŻöM╚╬║╬╬┤üĒĄ─ū▀Ę©ĪŻ▀@š╣╩Š┴╦║åå╬Ą─╔ŅČ╚╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)īW(xu©”)┴Ģ(x©¬)Ą─┴”┴┐ĪŻ
Ė³┐ņĄ─┬õūė▀xō±Ų„
AlphaGo«ö(d©Īng)╚╗łFĻĀø]ėąį┌▀@└’ų╣▓ĮĪŻŽ┬├µ╬ęĢ■ĻU╩÷╩Ū╚ń║╬īóķåūx─▄┴”┘xėĶAIĄ─ĪŻ×ķ┴╦ū÷ĄĮ▀@ę╗³cŻ¼╦¹éāąĶę¬Ė³┐ņ░µ▒ŠĄ─┬õūė▀xō±Ų„┤¾─XĪŻįĮÅŖĄ─░µ▒Šį┌║─Ģr╔ŽįĮŠ├ŻŁ×ķ┴╦«a(ch©Żn)╔·ę╗éĆ▓╗ÕeĄ─┬õūėę▓ūŃē“┐ņ┴╦Ż¼Ą½“ķåūxĮY(ji©”)śŗ(g©░u)”ąĶę¬╚źÖz▓ķÄūŪ¦ĘN┬õūė┐╔─▄ąį▓┼─▄ū÷øQČ©ĪŻ
SilverłFĻĀĮ©┴ó║åå╬Ą─┬õūė▀xō±Ų„╚źū÷│÷“┐ņ╦┘ķåūx”Ą─░µ▒ŠŻ¼╦¹éāĘQų«×ķ“ØLäėŠW(w©Żng)Įj(lu©░)”ĪŻ║åå╬░µ▒Š╩Ū▓╗Ģ■┐┤š¹éĆ19*19Ą─ŲÕ▒PŻ¼Ą½Ģ■į┌ī”╩ųų«Ū░Ž┬Ą─║═ą┬Ž┬Ą─ŲÕūėųą┐╝æ]Ż¼ė^▓ņę╗éĆĖ³ąĪĄ─┤░┐┌ĪŻ╚źĄ¶▓┐Ęų┬õūė▀xō±Ų„┤¾─XĢ■ōp╩¦ę╗ą®īŹ┴”Ż¼Ą½▌p┴┐╝ē░µ▒Š─▄ē“▒╚ų«Ū░┐ņ1000▒ČŻ¼▀@ūī“ķåūxĮY(ji©”)śŗ(g©░u)”│╔┴╦┐╔─▄ĪŻ
Ą┌Č■┤¾─XŻ║ŲÕŠųįu╣└Ų„ Ż©Position EvaluatorŻ®
AlphaGoĄ─Ą┌Č■éĆ┤¾─XŽÓī”ė┌┬õūė▀xō±Ų„╩Ū╗ž┤┴Ēę╗éĆå¢Ņ}ĪŻ▓╗╩Ū╚ź▓┬£yŠ▀¾wŽ┬ę╗▓ĮŻ¼╦³ŅA(y©┤)£y├┐ę╗éĆŲÕ╩ų┌AŲÕĄ─┐╔─▄Ż¼į┌ĮoČ©ŲÕūė╬╗ų├ŪķørŽ┬ĪŻ▀@“Šų├µįu╣└Ų„”Š═╩Ūšō╬─ųą╠ߥĮĄ─“ārųĄŠW(w©Żng)Įj(lu©░)Ż©Value Network)”Ż¼═©▀^š¹¾wŠų├µ┼ąöÓüĒ▌oų·┬õūė▀xō±Ų„ĪŻ▀@éĆ┼ąöÓāHāH╩Ū┤¾Ė┼Ą─Ż¼Ą½ī”ė┌ķåūx╦┘Č╚╠ßĖ▀║▄ėąÄ═ų·ĪŻ═©▀^ĘųŅÉØōį┌Ą─╬┤üĒŠų├µĄ─“║├”┼c“ē─”Ż¼AlphaGo─▄ē“øQČ©╩Ūʱ═©▀^╠ž╩ŌūāĘN╚ź╔Ņ╚ļķåūxĪŻ╚ń╣¹Šų├µįu╣└Ų„šf▀@éĆ╠ž╩ŌūāĘN▓╗ąąŻ¼─Ū├┤AIŠ═╠°▀^ķåūxį┌▀@ę╗ŚlŠĆ╔ŽĄ─╚╬║╬Ė³ČÓ┬õūėĪŻ

Šų├µįu╣└Ų„╩Ūį§├┤┐┤▀@éĆŲÕ▒PĄ─ĪŻ╔Ņ╦{╔½▒Ē╩ŠŽ┬ę╗▓Įėą└¹ė┌┌AŲÕĄ─╬╗ų├ĪŻ
Šų├µįu╣└Ų„ę▓═©▀^░┘╚f╝ēäeĄ─ŲÕŠųū÷ė¢(x©┤n)ŠÜĪŻSilverłFĻĀ═©▀^ Å═(f©┤)ųŲā╔éĆAlphaGoĄ─ūŅÅŖ┬õūė▀xō±Ų„Ż¼Š½ą─╠¶▀xļSÖCśė▒Šäō(chu©żng)įņ┴╦▀@ą®Šų├µĪŻ▀@└’AI ┬õūė▀xō±Ų„į┌Ė▀ą¦äō(chu©żng)Į©┤¾ęÄ(gu©®)─ŻöĄ(sh©┤)ō■(j©┤)╝»╚źė¢(x©┤n)ŠÜŠų├µįu╣└Ų„╩ŪĘŪ│ŻėąārųĄĄ─ĪŻ▀@ĘN┬õūė▀xō±Ų„ūī┤¾╝ę╚ź─ŻöM└^└m(x©┤)═∙Ž┬ū▀Ą─║▄ČÓ┐╔─▄Ż¼Å─╚╬ęŌĮoČ©ŲÕ▒PŠų├µ╚ź▓┬£y┤¾ų┬Ą─ļpĘĮ┌AŲÕĖ┼┬╩ĪŻČ°╚╦ŅÉĄ─ŲÕŠų▀Ć▓╗ē“ČÓ┐ų┼┬ļyęį═Ļ│╔▀@ĘNė¢(x©┤n)ŠÜĪŻ
į÷╝ėķåūx
▀@└’ū÷┴╦╚²éĆ░µ▒ŠĄ─┬õūė▀xō±┤¾─XŻ¼╝ė╔ŽŠų├µįu╣└┤¾─XŻ¼AlphaGo┐╔ęįėąą¦╚źķåūx╬┤üĒū▀Ę©║═▓Į¾E┴╦ĪŻķåūxĖ·┤¾ČÓöĄ(sh©┤)ć·ŲÕAIę╗śėŻ¼═©▀^├╔╠ž┐©┬Õśõ╦č╦„Ż©MCTSŻ®╦ŃĘ©üĒ═Ļ│╔ĪŻĄ½AlphaGo▒╚Ųõ╦¹AIČ╝ę¬┬ö├„Ż¼─▄ē“Ė³╝ėųŪ─▄Ą─▓┬£y──éĆūāĘN╚ź╠Į£yŻ¼ąĶę¬ČÓ╔Ņ╚ź╠Į£yĪŻ
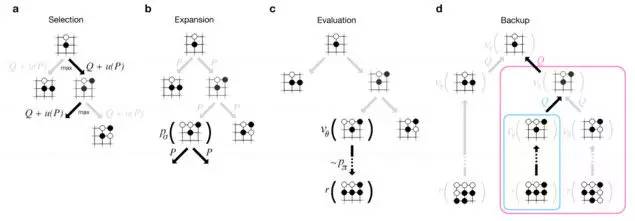
├╔╠ž┐©┬Õśõ╦č╦„╦ŃĘ©
╚ń╣¹ōĒėą¤oŽ▐Ą─ėŗ╦Ń─▄┴”Ż¼MCTS┐╔ęį└Ēšō╔Ž╚źėŗ╦ŃūŅ╝č┬õūė═©▀^╠Į╦„├┐ę╗ŠųĄ─┐╔─▄▓Į¾EĪŻĄ½╬┤üĒū▀Ę©Ą─╦č╦„┐šķgī”ė┌ć·ŲÕüĒšf╠½┤¾┴╦Ż©┤¾ĄĮ▒╚╬ęéāšJ(r©©n)ų¬ėŅųµ└’Ą─┴Żūė▀ĆČÓŻ®Ż¼īŹļH╔ŽAIø]ėą▐kĘ©╠Į╦„├┐ę╗éĆ┐╔─▄Ą─ūāĘNĪŻMCTSū÷Ę©▒╚Ųõ╦¹AIėąČÓ║├Ą─įŁę“╩Ūį┌ūRäeėą└¹Ą─ūāĘNŻ¼▀@śė┐╔ęį╠°▀^ę╗ą®▓╗└¹Ą─ĪŻ
SilverłFĻĀūīAlphaGočb╔ŽMCTSŽĄĮy(t©»ng)Ą──ŻēKŻ¼▀@ĘN┐“╝▄ūīįO(sh©©)ėŗš▀╚źŪČ╚ļ▓╗═¼Ą─╣”─▄╚źįu╣└ūāĘNĪŻūŅ║¾±R┴”╚½ķ_Ą─AlphaGoŽĄĮy(t©»ng)░┤╚ńŽ┬ĘĮ╩Į╩╣ė├┴╦╦∙ėą▀@ą®┤¾─XĪŻ
1. Å─«ö(d©Īng)Ū░Ą─ŲÕ▒P▓╝ŠųŻ¼▀xō±──ą®Ž┬ę╗▓ĮĄ─┐╔─▄ąįĪŻ╦¹éāė├╗∙ĄA(ch©│)Ą─┬õūė▀xō±Ų„┤¾─XŻ©╦¹éāćLįć╩╣ė├Ė³ÅŖĄ─░µ▒ŠŻ¼Ą½╩┬īŹ╔ŽūīAlphaGoĖ³╚§Ż¼ę“×ķ▀@ø]ėąūīMCTS╠ß╣®Ė³ÅVķ¤Ą─▀xō±┐šķgŻ®ĪŻ╦³╝»ųąį┌“├„’@ūŅ║├”Ą─┬õūėČ°▓╗╩Ūķåūx║▄ČÓŻ¼Č°▓╗╩Ūį┘╚ź▀xō±ę▓įSī”║¾üĒėą└¹Ą─Ž┬Ę©ĪŻ
2. ī”ė┌├┐ę╗éĆ┐╔─▄Ą─┬õūėŻ¼įu╣└┘|(zh©¼)┴┐ėąā╔ĘNĘĮ╩ĮŻ║ę¬├┤ė├ŲÕ▒P╔ŽŠų├µįu╣└Ų„į┌┬õūė║¾Ż¼ę¬├┤▀\ąąĖ³╔Ņ╚ļ├╔╠ž┐©┴_─ŻöMŲ„Ż©ØLäėŻ®╚ź╦╝┐╝╬┤üĒĄ─┬õūėŻ¼╩╣ė├┐ņ╦┘ķåūxĄ─┬õūė▀xō±Ų„╚ź╠ßĖ▀╦č╦„╦┘Č╚ĪŻAlphaGo╩╣ė├║åå╬ģóöĄ(sh©┤)Ż¼“╗ņ║ŽŽÓĻP(gu©Īn)ŽĄöĄ(sh©┤)”Ż¼īó├┐ę╗éĆ▓┬£y╚ĪÖÓ(qu©ón)ųžĪŻūŅ┤¾±R┴”Ą─AlphaGo╩╣ė├ 50/50Ą─╗ņ║Ž▒╚Ż¼╩╣ė├Šų├µįu╣└Ų„║═─ŻöM╗»ØLäė╚źū÷ŲĮ║Ō┼ąöÓĪŻ
▀@Ų¬šō╬─░³║¼ę╗éĆļSų°╦¹éā╩╣ė├▓Õ╝■Ą─▓╗═¼Ż¼AlphaGoĄ──▄┴”ūā╗»║═╔Ž╩÷▓Į¾EĄ──ŻöMĪŻāH╩╣ė├¬Ü┴ó┤¾─XŻ¼AlphaGoĖ·ūŅ║├Ą─ėŗ╦ŃÖCć·ŲÕAI▓Ņ▓╗ČÓÅŖŻ¼Ą½«ö(d©Īng)╩╣ė├▀@ą®ŠC║Ž╩ųČ╬Ż¼Š═┐╔─▄ĄĮ▀_┬ÜśI(y©©)╚╦ŅÉ▀x╩ų╦«ŲĮĪŻ
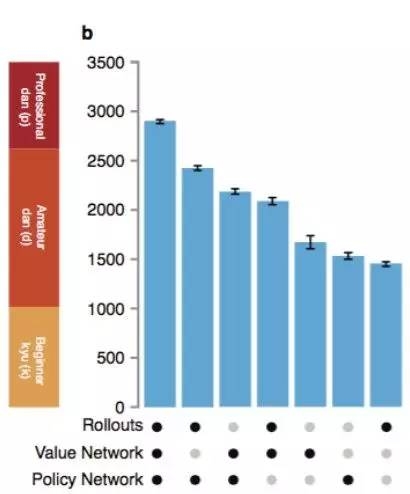
AlphaGoĄ──▄┴”ūā╗»┼cMCTSĄ─▓Õ╝■╩Ūʱ╩╣ė├ėąĻP(gu©Īn)
▀@Ų¬šō╬─▀Ćįö╝Üųv┴╦ę╗ą®╣ż│╠ā×(y©Łu)╗»Ż║Ęų▓╝╩Įėŗ╦ŃŻ¼ŠW(w©Żng)Įj(lu©░)ėŗ╦ŃÖC╚ź╠ß╔²MCTS╦┘Č╚Ż¼Ą½▀@ą®Č╝ø]ėąĖ─ūā╗∙ĄA(ch©│)╦ŃĘ©ĪŻ▀@ą®╦ŃĘ©▓┐ųąĘųŠ½┤_Ż¼▓┐ĘųĮ³╦ŲĪŻį┌╠žäeŪķørŽ┬Ż¼AlphaGo═©▀^Ė³ÅŖĄ─ėŗ╦Ń─▄┴”ūāĄ─Ė³ÅŖŻ¼Ą½ėŗ╦Ńå╬į¬Ą─╠ß╔²┬╩ļSų°ąį─▄ūāÅŖČ°£pŠÅĪŻ
╚╗Č°Ż¼AlphaGo▀Ć▀h▓╗╩Ūšµš²Ą─╚╦╣żųŪ─▄
AlphaGo½@ä┘Ż¼ūī║▄ČÓ╚╦ą─└’Ė³╝ė╗╠┐ųŻ¼▓╗Š├Ą─╬┤üĒŻ¼ÖCŲ„╚╦╩ŪʱŠ═Ģ■╚Ī┤·┤¾▓┐Ęų╚╦ŅÉĄ─╣żū„Ż¼╔§ų┴?x©¬)■Įy(t©»ng)ų╬╚╦ŅÉ─žŻ┐Å─AlphaGo─┐Ū░Ą─╦«ŲĮüĒ┐┤Ż¼▀@╩Ū▓╗┐╔─▄Ą─Ż¼Ž╚Įo┤¾╝ęę╗éĆ░▓ą─Ą─ĮY(ji©”)šōŻ¼AlphaGo▀Ć▀h▓╗╩Ūšµš²Ą─╚╦╣żųŪ─▄Ż¼ę▓ø]ėąšQ╔·šµš²Ą─ųŪ─▄Ż¼Ģ■Ž┬ć·ŲÕĖ·šQ╔·ųŪ─▄╩Ūā╔┤a╩┬ŪķŻ¼Ž┬ŲÕ║▄ģ¢║”Ą─╚╦╣żųŪ─▄Ė·šµš²Ą─ŅÉ╚╦ųŪ─▄AIę▓╩Ūā╔┤a╩┬ŪķĪŻ
ųžą┬╗žĄĮ▀@ł÷éõ╩▄▓Ü─┐Ą─╚╦ÖC┤¾æ(zh©żn)Ż¼ūī╬ęéāüĒ║├║├Ęų╬÷ę╗Ž┬AlphaGoĄĮĄū╩Ūį§├┤Ž┬ŲÕĄ─ĪŻ
╩ūŽ╚Ż¼ūį╬ęī”▐─ÄūŪ¦╚fŠųĄ├│÷░óĀ¢Ę©╣Ę├µī”└Ņ╩└╩»┐╔ęį├ļ┬õūėŻ¼▀@éĆ▓ó▓╗ć└(y©ón)ųö(j©½n)ĪŻAlphaGoų╗╩ŪéĆę²ŪµŻ¼╦³Ą──ŪÄūŪ¦╚fŠųūį╬ęī”Šųė¢(x©┤n)ŠÜĖ·▀@┤╬Ž┬ŲÕ▒╚┘É╩Ū═Ļ╚½▓╗═¼Ą─ĪŻė¢(x©┤n)ŠÜĄ─Ģr║“AlphaGo╩Ū▀BĮėų°╚½Ū“ūŅ║└╚AĄ─╣╚ĖĶįŲŠW(w©Żng)Įj(lu©░)öĄ(sh©┤)ō■(j©┤)ĪóįŲėŗ╦ŃŠW(w©Żng)Įj(lu©░)Ż¼ėąöĄ(sh©┤)Ū¦┼_Ę■äš(w©┤)Ų„üĒģf(xi©”)ų·╦³▀Mąąī”Šųė¢(x©┤n)ŠÜŻ¼ęį▀_ĄĮ┐ņ╦┘╠ß╔²Ą──┐Ą─ĪŻČ°▀@┤╬▒╚┘ÉųąAlphaGo╩Ū▒╗Į¹ų╣┬ō(li©ón)ŠW(w©Żng)ęįĘ└ų╣ū„|▒ūŻ¼╝ā┤Ōę└┐┐ūį╔ĒüĒæ¬(y©®ng)ī”Šų├µĪŻ’@╚╗▀@Č■š▀▀MąąĢr╦³Ą─▀\╦Ń─▄┴”╩Ū═Ļ╚½▓╗═¼Ą─Ż¼īŹļH╔ŽAlphaGoę▓▓óø]ėą│÷¼F(xi©żn)╦∙ų^Ą─├ļ┬õūėĄ─ŪķørŻ¼«ö(d©Īng)╚╗╦³ėŗ╦Ń╦∙╗©Ą─Ģrķg╩ŪśOČ╠Ą─ų°╩Ū║┴¤oę╔å¢Ą─ĪŻ
Ųõ┤╬Ż¼├ļ┬õūė▀@╝■╩┬▒Š╔Ē▓óø]ėąČÓ├┤┐╔┼┬Ż¼▀@éĆ╩ŪĮ©┴óį┌ėŗ╦ŃÖCÅŖ┤¾Ą─ėŗ╦Ńąį─▄╔ŽĄ─Ż¼┼cAIĄ─ųŪ─▄│╠Č╚ę▓ø]ČÓ┤¾ĻP(gu©Īn)ŽĄĪŻć·ŲÕĄ─ęÄ(gu©®)Šžö[į┌─Ū└’Ż¼Š═╦Ń└Ņ╩└╩»┬õę╗ūėŻ¼ļŖ─XĖ·ų°├ļ┬õūėĪŻ╚╗║¾─žŻ┐╚╗║¾╦¹▀Ć╩Ūꬥ╚└Ņ╩└╩»┬õŽ┬ę╗ūėų«║¾╦³▓┼─▄Įėų°Ž┬Ż¼▓╗┤µį┌šf▓╗Įo└Ņ╩└╩»╦╝┐╝Ą─ĢrķgĪŻŠ═╦Ń─Ń╩Ū├ļŽ┬Ż¼╚╦╝ę▓ó▓╗╩ŪŻ¼ć·ŲÕ╩Ū╗ž║ŽųŲŻ¼─Ńį┘┐ņŽ┬═Ļ┴╦ę▓Ą├Ą╚╚╦╝ęĮė┴╦▓┼─▄ū▀Ž┬ę╗▓ĮĪŻ
Å─īŹļHüĒ┐┤ę▓╩Ū╚ń┤╦ĪŻų┴ė┌Ž¹║─Ą─Ģrķg▒Š╔Ēę▓▓╗ļy└ĒĮŌŻ¼ė▓╝■ąį─▄║═╦ŃĘ©▒Š╔ĒČ╝ėąéĆŠųŽ▐ąįį┌─Ū└’Ż¼╦∙ęįī”ė┌ėŗ╦ŃÖCüĒšfŻ¼╦³╝╚┐╔ęį┐╔ęį├ļŽ┬Ż¼ę▓┐╔ęįėŗ╦ѤoŽ▐ķLĄ─ĢrķgĪŻ
┼eéĆ└²ūėŻ¼╚ń╣¹╩ŪĮoę╗Ą└öĄ(sh©┤)īW(xu©”)ėŗ╦ŃŅ}Ż¼ę¬╚╦║═ļŖ─X╦ŃĮY(ji©”)╣¹ĪŻ╚╦ę¬╦Ń╩«ĘųńŖŻ¼ėŗ╦ŃÖCę╗├ļ▓╗ĄĮŠ═ē“┴╦Ż¼▀@╩Ū┤_┤_īŹīŹėŗ╦Ń─▄┴”Ą─▓ŅŠÓŻ¼ę“×ķ▀@Ą└Ņ}ĮY(ji©”)╣¹╩Ū╬©ę╗Ą─Ż¼╩Ūėąś╦(bi©Īo)£╩(zh©│n)┤░ĖĄ─ĪŻĄ½ć·ŲÕ▓╗═¼Ż¼▓╗┤µį┌─Ńę╗├ļńŖšęĄĮ┴╦éĆūŅā×(y©Łu)ĮŌŻ¼ę“×ķ▒ŠüĒŠ═¤o╦∙ų^ūŅā×(y©Łu)ĮŌŻ¼║¾└m(x©┤)ėą¤oĖFĄ─ūā╗»ĪŻ╗©┘MĄ─ĢrķgČ╠Ż¼ų╗╩Ūėŗ╦Ń┐╝æ]Ą─ŪķørŠ═įĮ╔┘ĪŻ«ö(d©Īng)╚╗╗©┘MĄ─ĢrķgČÓŻ¼╦ŃĄ├įĮČÓŻ¼ę▓▓╗┤·▒ĒŠ═įĮš²┤_ĪŻ
╦∙ęį▀@éĆ╦╝┐╝Ģrķgšf├„▓╗┴╦╩▓├┤Ż¼▀@└’▒ŠüĒŠ═╩ŪÖCŲ„Ą─ķL╠Ä╦∙į┌Ż¼╦ŃĄ├▒╚╚╦ŅÉ┐ņ║▄š²│ŻĪŻ╚ń╣¹╦ŃĄ─ĢrķgķLę▓ų╗─▄šf├„╦³ėŗ╦ŃĄ├Ė³įö╝ÜĖ³Å═(f©┤)ļsęį┴”łDīżŪ¾Ė³║├Ą─┐╔─▄Ż¼ę▓ī┘š²│ŻĪŻ
╦∙ęįšfŻ¼AlphaGo╦∙ų^Ą─“╦╝┐╝”Ż¼▒Š┘|(zh©¼)╔Ž▀Ć╩ŪĖ·╚╦ŅÉŲÕ╩ųę╗śėĄ─ĪŻų╗╩Ūį┌─ŻöM║═ŅA(y©┤)£yų«║¾ŲÕŠųĄ─ūā╗»Ż¼▀@Ė·╬ęéā╦∙šfĄ─│¼╝ē╚╦╣żųŪ─▄Ą─╦╝Žļėą▒Š┘|(zh©¼)ģ^(q©▒)äeĪŻ▀@└’╩Ū│¼╝ēļŖ─Xį┌īŻśI(y©©)ŅI(l©½ng)ė“æ(zh©żn)ä┘╚╦ŅÉĄ─å¢Ņ}Ż¼─Ū╩ŪŅÉ╦Ųų°├¹Ą─“╣╩ęŌ▓╗═©▀^łDņ`£yį攥─AI╚╦ąį╗»å¢Ņ}ĪŻ
Å─▀@éĆ▒╚┘ÉŻ¼─┐Ū░ų╗─▄┐┤│÷AlphaGoŽ┬ŲÕģ¢║”Ż¼Č°ø]┐┤│÷üĒ╦³ČÓ├┤Ž±╚╦ĪŻ╦³─┐Ū░ø]ėą╩▓├┤▀`Ę┤│Ż└ĒĄ─ąą×ķŻ¼╦³¾w¼F(xi©żn)│÷üĒĄ─ÅŖ┤¾╩Ūį┌╝āæ{▀ē▌ŗĘų╬÷═Ų╦ŃĄ──▄┴”╔ŽÅŖ┤¾¤o▒╚Ż¼Ą½╩ŪŲõįŁ└Ē▓óĘŪŅÉ╚╦╚╦╣żųŪ─▄Ż¼▓óø]ėą▒Ē¼F(xi©żn)│÷ĖąŪķŻ¼╦³╚į╩Ū▒∙└õĄ─ÖCŲ„ĪŻ╦³½@ä┘┴╦Ż¼ę▓Š═½@ä┘┴╦Ż¼ø]ėąūį╝║Įoūį╝║öÓéĆļŖüĒē║ē║¾@ĪŻ
ūóęŌ——╚╦╣żųŪ─▄▀ē▌ŗĘų╬÷║═ėŗ╦ŃøQ▓▀Ą╚─▄┴”ūāĄ├▒╚╚╦ŅÉģ¢║”Ż¼║═╚╦╣żųŪ─▄ūāĄ├Ė³Ž±ę╗éĆšµš²Ą─╚╦ŅÉŻ¼▀@Č■š▀╩Ūėąģ^(q©▒)äeĄ─ĪŻAlphaGo’@╚╗▓╗ī┘ė┌║¾š▀Ą─ŪķørŻ¼╦³Ą─šQ╔·║═░l(f©Ī)š╣╩Ū▓ó▓╗╩Ū×ķ┴╦ūāĄ├Ė³Ž±ę╗éĆšµ╚╦Ż¼Č°╩Ū│ąō·(d©Īn)ų°į┌ėŗ╦ŃÖC╔├ķLĄ─ŅI(l©½ng)ė“┤·╠µ╚╦ŅÉ═Ļ│╔─Ūą®╩▄Ž▐ė┌╚╦─Xėŗ╦Ń─▄┴”╦∙▓╗─▄ĮŌøQĄ─▀\╦ŃøQ▓▀å¢Ņ}Ą─ųž╚╬ĪŻ╦³Ž┬ŲÕęčĮø(j©®ng)ūŃē“ā×(y©Łu)ąŃŻ¼Ą½╩ŪļxÅVĘ║īŹė├Ą─ėŗ╦ŃŲĮ┼_▀Ć▓ŅĄ├▀hĪŻĄ½╩Ū«ģŠ╣╩ŪŠ▐┤¾Ą─▀M▓ĮŻ¼╦³Ą─╬┤üĒ╩Ūū„×ķ╚╦ŅÉĄ─ų·└ĒŻ¼╚ź╠Ä└Ē─Ūą®╝ā▀ē▌ŗĘų╬÷Ą─å¢Ņ}Ż╗Č°▓╗╩Ūū„×ķ╚╦ŅÉĄ─╗’░ķŻ¼üĒĖ·─ŃĮ╗┴„ī”įÆĪŻ
╦∙ęįŻ¼AlphaGo─┐Ū░▀Ćų╗╩ŪéĆŽ┬ŲÕÖCŲ„Č°ęčĪŻŲÕ╩ųĖ·╦³Ž┬ŲÕ┼cĖ·╚╦Ž┬ŲÕę▓╩Ū▓╗═¼Ą─ĪŻŽ┬ŲÕ▒Š╔Ēę▓╩Ūę╗ĘNĮ╗┴„Ż¼▀@éĆ║▄ČÓ┤¾Ä¤Č╝ųv▀^Ż¼╔į╬óī”ć·ŲÕ╬─╗»┴╦ĮŌĄ─╚╦ę▓Č╝ų¬Ą└ĪŻć·ŲÕĄ─„╚┴”Į^▓╗āHāHį┌ė┌ėŗ╦ŃĪŻī”Šųę▓╩Ūę╗ĘNĮ╗┴„Ż¼ŲÕ╩ųĄ─ąįĖ±Īóą─æB(t©żi)ę▓Ģ■ė░Ēæ┬õūėĄ─┼ąöÓŻ¼ī”ė┌ī”╩ųĄ─ą─æB(t©żi)ĪóąįĖ±Ą─╣└ėŗę▓Ģ■ėŗ╚ļī”ŠųĄ─┐╝┴┐Ż¼▀@▓óĘŪ╝ā└Ēąį╦╝┐╝Ą─Ėé┘ÉŻ¼▀@ę▓╩Ūć·ŲÕ▒╚┘É║═ŲÕ╩ųīŹ┴”Ą─ę╗▓┐ĘųĪŻ╚╗Č°į┌AlphaGo├µŪ░▀@ą®Č╝▓╗┤µį┌Ż¼╦³¤o╦∙╬Ęæųę▓▓╗Ģ■ŠoÅłĪŻ└Ņ╩└╩»ę▓▓╗ąĶę¬╚ź┐╝æ]AlphaGoėą╩▓├┤ŽļĘ©ĪŻ▀@╩Ū▒╚Ž┬ŲÕŻ¼▓ó▓╗╩Ū▒╚«ŗ«ŗ╗“š▀īæįŖĪŻ
╦∙ęį▀@ē║Ė∙▓╗─▄╦Ń╩ŪéĆėæšōAI╩Ūʱšµš²šQ╔·ųŪ─▄Ą─└²ūėŻ¼╬ęéāę▓¤oąĶō·(d©Īn)ænĪŻAlphaGo┤·▒ĒĄ─╩Ū┴Ēę╗éĆŅI(l©½ng)ė“Ą─’@ų°▀M▓ĮŻ¼┤·▒ĒĄ─╩Ū╬┤üĒ╚½ą┬Ą─Ū░Š░ĪŻĄ½Š═Ž±└Ņķ_Å═(f©┤)╦∙šfĄ─ę╗śėŻ¼╬ęéāšµš²ę¬ō·(d©Īn)ą─Ą─Ż¼╩Ū▀@ą®Ę▒¼ŹĄ─ėŗ╦Ń║═╦╝┐╝Č╝┐╔ęįė╔ļŖ─XüĒ═Ļ│╔ų«║¾Ż¼«ö(d©Īng)┼K╗Ņ└█╗ŅČ╝┐╔ęį▒╗ÖCŲ„┤·╠µų«║¾Ż¼╚╦ŅÉĢ■▓╗Ģ■ūāĄ├▓╗╦╝▀M╚ĪŻ¼¤o╦∙╩┬╩┬Č°ķ_╩╝ēÖ┬õĘ┼┐vĪŻ
└Ņķ_Å═(f©┤)▒Ē╩ŠŻ¼AlphaGoļm╚╗║▄ģ¢║”Ż¼Ą½╩Ūšf░ū┴╦ŲõīŹ▀Ć╩Ūę╗éĆ┬ö├„Ą─ÖCŲ„Ż¼ōĒėąĖ▀╦┘Ą─╦╝┐╝║═▀\╦Ń─▄┴”Ż¼Ģ■Ä═ų·╬ęéāį┌┘Å┘I╣╔Ų▒Īóßt(y©®)»¤Ą╚ŅI(l©½ng)ė“ėą║▄║├Ą─Ä═ų·ĪŻ▓╗▀^ÖCŲ„ĮKÜwø]ėąŪķĖąŻ¼ų╗╩Ū╚╦ŅÉ╣żŠ▀Č°ęčŻ¼╦∙ęį╬ęéāų„ꬹĶę¬└¹ė├╚╦╣żųŪ─▄äō(chu©żng)įņĖ³┤¾Ą─╔╠śI(y©©)║═┐Ų╝╝ārųĄĪŻ