

Neeke Ė▀±YزŻ¼įŲųŪ╗█Ė▀╝ē╝▄śŗĤŻ¼PHPĖ▀╝ēķ_░lĮM│╔åTų«ę╗Ż¼╩ŪįŲųŪ╗█═ĖęĢīÜ«aŲĘĄ─║╦ą─čą░l│╔åTŻ¼ęįŽ┬╩Ū╦¹Ą─ĘųŽĒīŹõøŻ║
Ž╚Å─ę╗éĆäéäé░l╔·Ą─šµīŹ░Ė└²ķ_╩╝▀@┤╬ĘųŽĒŻ¼Į±╠ņĄ─ĘųŽĒčė▀t┴╦░ļéĆąĪĢrŻ¼įŁę“╩Ū╬ęäéäéį┌╠Ä└Ē═ĖęĢīÜQAŁhŠ│ųąĄ─ę╗éĆÕ┤ÖC╣╩šŽĪŻ
▀@éĆ╣╩šŽĄ─▒Ē¼F╩ŪŻ║æ¬ė├500Õeš`Ż¼¤oĘ©š²│ŻįLå¢Ż¼═¼Ģrė░Ēæ═ĖęĢīÜĪó▒O┐žīÜ║═╣½╣▓Ą─CWOPŲĮ┼_Ż¼įņ│╔Į³ā╔éĆąĪĢrĄ─£yįć▀MČ╚░c»łĪŻ
╠Ä└Ē▀^│╠Ż║▓ķ┐┤nginx╚šųŠŻ¼░l¼Fėąupstream▓╗─▄├³ųąå¢Ņ}Ż¼health check─ŻēKŅlĘ▒ł¾ÕeŻ¼┼┼▓ķų«║¾░l¼F╩Ūę╗éĆ║¾Č╦Įė┐┌Å─upstreamųąĄ¶ŠĆŻ¼╚╗Č°▀@éĆ╣╩šŽ▓ó▓╗╩Ūī¦ų┬Õ┤ÖCĄ─Ė∙▒ŠįŁę“ĪŻ
Å─upstreamųą╠▀Ą¶įōĘ■äš║¾Ż¼└^└m┼┼▓ķŻ║▓ķ┐┤apache╚šųŠŻ¼░l¼FnginxīóšłŪ¾š²│ŻĄž▐D░lĄĮ┴╦apacheĘ■䚯¼apacheĘ■äšĘĄ╗ž500ĮonginxŻ¼nginx▐DōQ500Õeš`Ēō║¾Æü│÷Ż¼š²│ŻĄ─500Õeš`ęčĮø▓╗─▄š²│ŻĄžĒææ¬ĪŻ
š{š¹nginxÆü│÷š²│Ż500║¾Ż¼└^└m┼┼▓ķŻ¼ļm╚╗QA─ŻöM╔·«aŁhŠ│Ż¼Ą½▓óø]ėąæ¬ėąĄ─ē║┴”ęÄ─ŻŻ¼ė┌╩Ū▓╗æ¬│÷¼F┤¾┴„┴┐║ķĘÕŻ¼▓ķ┐┤nginx║═apacheĀŅæBĒō║¾Ż¼┤_šJŻ¼└^└m┼┼▓ķŻ╗╗∙▒Š╔Žå¢Ņ}Č©╬╗į┌æ¬ė├▒Š╔ĒŻ╗▓ķ┐┤æ¬ė├▒Š╔ĒĄ─logŻ¼Ė„ĘNless more grepę╗═©Ż¼ø]ėą░l¼F«É│Ż╚šųŠŻ¼▀@Ģrę╗░Ń╚╦ā║╣└ėŗę¬ūź┐±┴╦ĪŻ
╬ęė├┴╦═ĖęĢīÜĄ─PHPAgentŻ¼▀Mąą╣╩šŽ┼┼▓ķŻ¼Č©╬╗å¢Ņ}┤¾╝s╗©┴╦1ĘųńŖ,

╣╩šŽĄ─Ė∙į┤╩ŪQAĄ─DB▒╗┤“Æņ┴╦Ż¼║¾üĒĮø┤_šJŻ¼╩Ū▒O┐žīÜĄ─QA═¼╩┬į┌┼▄ę╗éĆė├æ¶╠Ä└Ē─_▒ŠĪŻ═¼Ģrī¦ų┬▒╗┤“ÆņĄ─▀ĆėąRedisĪŻ
![]()
▀@║══ĖęĢīÜĄ─PHPAgentø]ėąĻPŽĄ░ĪŻ┐
ėąĻPŽĄŻĪ▀@╩ŪPHPAgentĄ─trace_error║═trace_exception▀xĒŚŻ¼┤“│÷Ą─╚šųŠĪŻ▀@ĒŚ╣”─▄ęčĮøį┌£yįćųąŻ¼╝┤īóš²╩Į░l▓╝╔ŽŠĆĪŻ
ūŅĮKĮŌøQå¢Ņ}ĘĮ░ĖĘŪ│Ż║åå╬Ż║ ĻPķ]nginxŻ¼ĻPķ]apacheŻ¼ųžåómysql, ųžåóredisŻ¼ųžåóapacheŻ¼ųžåónginxĪŻ“×ūC▒O┐žīÜĪó═ĖęĢīÜ║═CWOPŲĮ┼_Ż¼╗ųÅ═ĪŻ
▀@éĆ░Ė└²Ą─æ¬ė├ł÷Š░╩ŪŻ║
ė├æ¶į┌╔·«aŁhŠ│ųąĢ■ė÷ĄĮĖ„ĘNę“öĄō■╗“┴„┴┐Īó┤·┤aĄ╚įņ│╔Ą─Õeš`║═«É│ŻŻ¼Č°▀@ą®Õeš`║═«É│Żų«Ū░▓óø]ėąė÷ĄĮ▀^Ż¼ę“┤╦Õeš`║═«É│Ż▓ó╬┤▒╗ĻPūóŻ¼┤╦ĢrĮŌøQå¢Ņ}ąĶę¬╩╣ė├APM«aŲĘ═ĖęĢĄ─Õeš`║═«É│Ż░l¼F╣”─▄ĪŻ
įō╣”─▄┐╔ęįūįäė▓ČūĮę“┘Yį┤ĪóĮė┐┌ĪóöĄō■╗“Ųõ╦¹įŁę“įņ│╔Ą─╬┤ŅAų¬«É│ŻŻ¼▓ó▀MąąģRł¾║═ĮyėŗĘų╬÷Ż¼ū÷ĄĮŠ½£╩╠ß╩Š║═ŅAŠ»Ż©ŅA£y╬┤üĒŻ®ĪŻ
įŲųŪ╗█APM«aŲĘ═ĖęĢīÜĄ─įOėŗ│§ųįŻ║
2. Å─ąį─▄╣▄└ĒĄ─ĮŪČ╚ča│õ▓ó│õĘųĄž┴╦ĮŌŲ¾śIæ¬ė├╝▄śŗ═žōõŻ╗
3. £╩┤_šęĄĮ▓óÄ═ų·ĮŌøQŲ¾śIæ¬ė├Ą─ąį─▄Ų┐Ņi³cŻ╗
4. ╩╣ė├ąį─▄╣▄└Ē┐ņ╦┘ĮŌøQå¢Ņ}Ż¼ęÄ▒▄Øōį┌Ą─æ¬ė├’LļUŻ¼Å─Č°╠ß╔²æ¬ė├ārųĄŻ╗
ę¬▀_ĄĮęį╔Ž─┐ś╦Ż¼╬ęéāąĶę¬ū÷ĄĮ▀@śėÄūéĆę¬³cŻ║
1. ę¬£╩┤_└ĒĮŌAPMĄ─šµš²║¼┴xĪŻ
APMĮ^▓╗āHāH╩Ū║åå╬Ą─╦┘Č╚▒O£y║═╚šųŠ╣▄└ĒĪŻ▓╗╔┘APMÅS╔╠Ż¼┐┤╦Ų┐ßņ┼Ą─Įń├µŻ¼ŲõīŹų╗╩Ūū÷┴╦ę╗éĆĘŪ│Ż║åå╬Ą─╚šųŠĮyėŗ╣▄└ĒĪŻAPM░³║¼Ą─ā╚╚▌ĘŪ│Ż╔ŅÅVŻ¼ÅS╔╠éāŽ▓Üg░č▀@ÅłłDÆü│÷üĒ║÷ėŲė├æ¶Ż¼Ą½╩Ūšµš²ū÷ĄĮĄ─APMĄ─Ż¼ŲõīŹ▓ó▓╗ČÓĪŻ

Ė∙ō■GartnerĄ─Č©┴xŻ¼šµš²Ą─APMę¬Ū¾ū÷ĄĮ5éĆĘČć·Ż║ĮKČ╦ė├涾w“ׯ¼æ¬ė├╝▄śŗė│╔õŻ¼æ¬ė├╩┬äšĘų╬÷Ż¼╔ŅČ╚æ¬ė├į\öÓŻ¼Ęų╬÷┼cł¾ĖµĪŻ
╚ź─Ļć°═Ōę╗╬╗Ęų╬÷Ĥū÷▀^ę╗┤╬Ęų╬÷ī”▒╚Ż¼┐╔ęįĘ┤ė│╚ź─ĻĄ─ŪķørŻ¼Į±─ĻąĶę¬į┘ū÷ę╗Ž┬ī”▒╚ĪŻ
2. Å─ĮKČ╦ė├涾w“×│÷░lŻ¼ū÷ĄĮöĄō■Ą─“Č╦”ĄĮ“Č╦”
ČÓ─ĻŪ░śIā╚Š═į┌╠ßEnd2EndŻ¼¼Fį┌śIā╚ÄūéĆÅS╔╠į┌└^įŲųŪ╗█╠ß│÷Č╦ĄĮČ╦Ė┼─Ņų«║¾Ż¼ę▓į┌▀@├┤▀║║╚ĪŻČ╦ĄĮČ╦ėą║▄ČÓĘN└ĒĮŌŻ¼╬ęéāĄ─└ĒĮŌ╩ŪŻ¼Å─ĮKČ╦ė├æ¶│÷░lŻ¼īóÅ─requestĄĮresponseš¹éƵ£┬Ęųą╔µ╝░ĄĮĄ─öĄō■Ż¼ėąą¦Ąž┤«ĮėŲüĒŻ¼▀@śėĄ─öĄō■▓┼╩Ūšµš²Ą─Č╦ĄĮČ╦ĪŻ
īŹ¼FĘĮ╩Įę▓▒╚▌^ų▒ĮėŻ¼Å─šłŪ¾ķ_╩╝«a╔·ę╗ų┬hashŻ¼įōhashīó░ķļSš¹éĆšłŪ¾▀^│╠Ż¼ę╗▓Įę╗▓ĮŽ“║¾╗“┼į▀Mąąé„▀fŻ¼▓óÅ─ūŅ─®╗“ūŅ┼įĄ─Ēææ¬ķ_╩╝Ż¼ę╗▓Įę╗▓ĮŽ“Ū░╗“┼į▀Mąą╗žæ¬ĪŻ
3. ė├æ¶ąą×ķöĄō■┼cąį─▄╣▄└ĒöĄō■Ą─ėąÖCĮY║Ž
ė├æ¶ąą×ķöĄō■╩Ū┤¾öĄō■ųąūŅļy┴Ņ╚╦ūĮ├■Ą─ę╗ŅÉöĄō■ĪŻ┤¾ČÓöĄŪķørŽ┬╚╦Ą─ąą×ķŽ▓║├╩Ū╣╠Č©Ą─Ż¼╗“ėąÄūéĆŲ½║├ĘĮŽ“ĪŻ╚ń╔½▓╩Ž▓║├Ż¼Ą┌ę╗ęĢ³cŽ▓║├Ż¼╔§ų┴ėąĄ─╚╦Ģ■ėą╠žČ©Ą─▀ģĮŪ³cō¶Ž▓║├ĪŻ▓╗═¼Ą─╬╗ų├╗“╔½▓╩Ą─░┤ŌoĪóµ£ĮėŻ¼┐╔─▄į┌▓╗═¼Ą─╔ŅČ╚Ģ■ī”æ¬ė├Ą─ąį─▄įņ│╔Įį╚╗▓╗═¼Ą─ė░ĒæĪŻ
═¼śėĄ─ę╗éĆ╣”─▄ĒŚŻ¼ė╔ė┌▓╗═¼Ą─Ž▓║├įOČ©Ż¼ę▓┐╔─▄Ģ■įņ│╔═Ļ╚½▓╗═¼Ą─ārųĄ¾w¼FĪŻ═ĖęĢīÜMobile SDK║═Web RumŻ¼Č╝ĘŪ│Żėč║├Ąžėøõøė├æ¶Ą─ąą×ķŽ▓║├Ż¼ąą×ķµ£┬ĘĪŻ
4. ╩╣ė├ųŪ─▄░l¼F╝╝ągŻ¼═Ļ│╔æ¬ė├┤·┤a▀\ąąĢrĄ─═žōõė│╔õĪŻ
╗∙ė┌ę¬³c2╦∙ųvĄ─“Č╦”ĄĮ“Č╦”īŹ¼FįŁ└ĒŻ¼×ķ─│ę╗éĆ╠žČ©Ą─šłŪ¾▀Mąą“╚Š╔½”╝ė╣żŻ¼▓╗ļyį┌öĄō■Ą─ūŅ╬┤“Č╦”£╩┤_Ą├ĄĮę╗┤╬šłŪ¾ųąĄ─šłŪ¾µ£┬ĘĪŻė┌╩Ū╬ęéā┐╔ęį╗∙ė┌┤╦ī”öĄęįā|╚fėŗĄ─ė├æ¶ąą×ķŻ¼┤„╔Žę╗éĆ“æ¬ė├”Ą─├▒ūėĪŻ
į┌▀@éĆ├▒ūėŽ┬├µŻ¼öĄō■▓╗į┘╩Ūę╗éĆéĆĄ─╣┬ŹuŻ¼Č°╩Ūėą╔·├³Ą─Į╗╠µ▐DōQĪŻ╬ęéā┐╔ęį£╩┤_ĄžĘų╬÷│÷ę╗éĆæ¬ė├Ą─╝▄śŗ═žōõŻ¼ėą──ą®žō▌dŠ∙║ŌŻ¼├┐┤╬šłŪ¾├³ųąĄ─╩Ū──ę╗éĆžō▌d³cŻ╗ę▓┐╔ęį£╩┤_ĄžĘų╬÷│÷ę╗éĆĘ■äš╝»╚║ųąŻ¼ėą──ą®ĮM│╔╣سcŻ¼├┐ę╗┤╬šłŪ¾Ż¼Š┐Š╣├³ųąĄ─╩Ū──ę╗éĆ╗“ČÓéĆ╣سcĪŻ╚ń▀@ÅłŲ»┴┴Ą─ų®ųļŠWŻ║

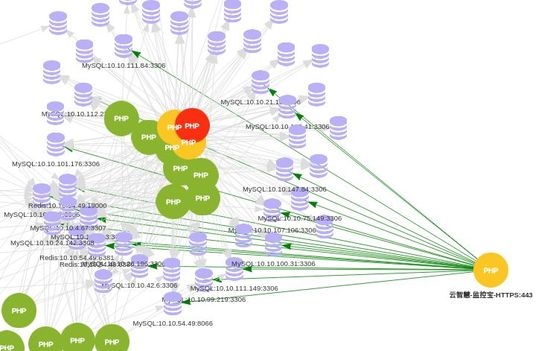
▀@į┌ŠSūoę╗éĆ┼fėąŽĄĮy╗“äéäéĮė╩ųĄ─ą┬ŽĄĮyĢrŻ¼╩ŪĘŪ│Żėąė├Ą─ĪŻį°ĮøĮėė|▀^╔Ņ█┌Ą─ę╗╝ę╔Ž╩ąŲ¾śIĄ─CTOŻ¼╦¹šf╦¹éāėą10ėÓ├¹╝▄śŗĤŻ¼ąĶę¬ė├░ļ─Ļų«Š├Ż¼▓┼─▄£╩┤_Ąž«ŗ│÷╦¹éāĄ─æ¬ė├═žōõĪŻ
5Ż«╩╣ė├ųŪ─▄╠Įßś╝╝ągŻ¼╚ĪĄ├╔Ņīė┤╬ąį─▄ųĖś╦ĪŻ
▀@└’ų°ųžę¬šfŠ═╩ŪSmartAgentĖ„éĆ▓Õ╝■Ą─īŹ¼FįŁ└ĒĪŻ╚ńPHPAgentäéäéĄ─ę╗┤╬æ¬ė├ĪŻį┌┼c²łųķĄ─║Žū„ųąŻ¼ę╗éĆ╠žäeėąęŌ╦╝Ą─ąĶŪ¾Ż¼╝┤╩ŪŻ║Įyėŗcache keyĄ─├³ųąĪŻ▓╗╩ŪÅ─cacheīė├µĮyė[Ą─statusŻ¼▀@śėĄ─ęŌ┴x▀^ė┌ŠųŽ▐Ż¼Č°╩ŪÅ─æ¬ė├īė├µŻ¼▀Mąą£╩┤_Ęų╬÷ĪŻ╚ńŻ║Įyėŗ─│ę╗éĆŠ▀¾wkeyĄ─├³ųą┬╩ĪŻÅ─▀@éĆīė├µŻ¼ąį─▄ųĖś╦Ą─╚ĪĄ├Ż¼ęčĮø▒╗┘xėĶ┴╦ĘŪ│Ż╔ŅĄ─ęŌ┴xĪŻ
6Ż«╔ŅČ╚Ęų╬÷Ė„ĒŚ┤¾öĄō■ųĖś╦Ż¼Ą├│÷ČÓŠSČ╚šłŪ¾æ¬┤Ą─╔ó³cą┼ŽóĪŻ
┤¾öĄō■ųĖś╦▓╗į┘ČÓšfŻ¼╬ęéāų°ųžšf“ČÓŠSČ╚”║═“╔ó³c”Ż¼▒╚╚ńšłŪ¾╩┬äšöĄō■ĪŻę╗éĆæ¬ė├ųąĄ─╩┬äš╗∙▒Š╩Ū▓╗┐╔├Č┼eĄ─Ż¼ę“×ķėąĖ„ĘNģóöĄĄ─┤µį┌Ż╗─Ū├┤į┌Ė„ĘNģóöĄ┤µį┌Ą─Ū░╠ß╔ŽŻ¼į§├┤ī”Ēææ¬Ģrķg▀MąąĮyėŗŻ┐
Ė„ÅS╔╠Ą─ū÷Ę©Ż║▀@Č╬Ģrķgā╚šłŪ¾ĢrķgūŅ┬²Ą─╩┬äštop10Ż¼▀@╩ŪŽÓ«ö▓╗žōž¤╚╬Ą─ū÷Ę©ĪŻ×ķ╩▓├┤▓╗žōž¤╚╬Ż║╬ęų¬Ą└▀@Š═╩Ū╬ęĄ─top10Ż¼╚╗║¾─žŻ┐╠ņ╠ņšf▀@éĆtop10Ż¼ų▄ų▄šfŻ¼į┬į┬šfŻ¼▀@▓ó▓╗─▄Ę┤ė│╬ęĄ─æ¬ė├ĮĪ┐ĄĀŅæBĪŻ╬ęéāąĶę¬ĻPūóĄ─╩ŪŻ¼─│Č╬Ģrķgā╚Ż¼šłŪ¾┤╬öĄėųČÓŻ¼Ēææ¬ĢrķgėųŽÓī”▌^┬²Ą─▀@ą®╩┬äšĪŻ
╦∙ęį╬ęéā╠ß│÷┴╦╚²éĆŠSČ╚Ą─Į╗▓µŻ║å╬╬╗Ģrķgā╚Ż¼šłŪ¾┤╬öĄŻ¼Ēææ¬ĢrķgĪŻ
ė┌╩Ū╬ęéā┐╔ęį«ŗ│÷ę╗Ę∙ŠžĻćłDŻ¼X▌S╩ŪĢrķgŻ¼ū¾Y▌S╩ŪšłŪ¾┤╬öĄŻ¼ėęY▌S╩ŪŲĮŠ∙Ēææ¬ĢrķgĪŻ▀@ą®╩┬äšęįŽ“┴┐╔ó┬õį┌▀@éĆŽ¾Ž▐ā╚Ż¼─Ū├┤╬ęéā┐╔ęįĄ├│÷Ż¼ŠÓļxXYĄ─ū¾įŁ³cŻ¼ŠÓļxūŅ▀hĄ─Ż¼╝┤╩Ū╬ęéā╦∙ĻPūóĄ─ĪŻ
Įø▀^│ķŽ¾║═«aŲĘ╩ß└ĒŻ¼╬ęéāĄ├│÷┴╦▀@śėĘŪ│ŻėąęŌ┴xĄ─Ęų╬÷ĮY╣¹Ż║
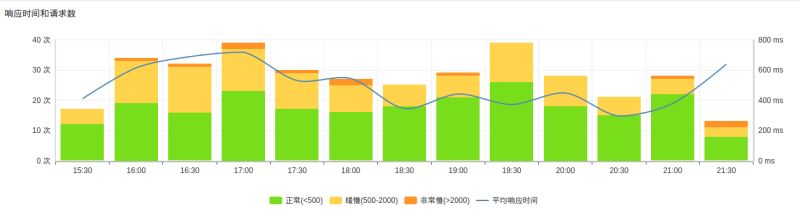

š¹éĆĒŚ─┐ī”ė┌╩┬䚥─ĮĪ┐ĄĘų╬÷ĀŅørŻ¼ę╗─┐┴╦╚╗Ż¼═¼Ģrėų┐╔ęį┐ņ╦┘šęĄĮĻPūó─┐ś╦ĪŻ
═ĖęĢīÜį┌Š▀¾wīŹ¼FųąŻ¼Įø▀^┴╦ČÓ┤╬īŹ█`║═č▌╗» ūŅĮKÄ═▀@ą®Ąõą═┐═æ¶ĮŌøQ┴╦▀@śėĘŪ│ŻīŹļHĄ─╚²éĆąĶŪ¾Ż║
1. Ä═ų·Ų¾śIĮŌøQŲš▒ķ┤µį┌Ą─“═ČįV╝┤Ę┤ü”Ą─ŪķørŻ¼ĘŪ│Żėą┴”Ą─Ė─╔Ų┴╦čą░lĪó▀\ŠSĪó╣▄└Ē╚╦åT▒╗äėĮė╩▄Ę┤üĄ─¼FĀŅŻ¼▒▄├Ō┴╦śI䚎┬ĮĄ║═ų▒ĮėĄ─ė├æ¶üG╩¦ĪŻ
2. Ä═ų·Ų¾śI╣▄└Ēš▀▒▄├Ō┴╦ĒŚ─┐ā×╗»╗“ųžśŗ▀^│╠ųąŻ¼├ż─┐Ą─ąį─▄Īó¾w“×ā×╗»Ż¼╠ß╣®┴╦ėąą¦Ą─ąį─▄Īó¾w“×ā×╗»Į©ūhŻ¼║═ŽÓī”æ¬Ą─│õĘųĄ─öĄō■ū¶ūCĪŻ
3. Ä═ų·Ų¾śIÄū║§¤o│╔▒ŠĄžĪó┴Ńą▐Ė─Ąž▀Mąąąį─▄Īó¾w“×▒O┐žĪŻ