
ųvŪ░Ž╚ŅA¤ßę╗Ž┬Ż¼╚ń╣¹ėą▀Ć▓╗╩ņŽżąĪ³SļuĄ─ėH~ÜgėŁ┤¾╝ę┤┴▀@└’http://mysimi.sinaapp.com/ ūįųŲąĪ³Sļuę╗├ČŻ¼ÜgėŁ£yįćĪŻĪŻĢ║ŪęĮą╦¹ąĪ³Sļu2╠¢~1╠¢į┌║¾├µ╣■
┤¾╝ę║├Ż¼╬ę╩ŪŃÕā║Ż¼Į±╠ņ║▄śsąęō·╚╬ų„ųvŻ¼┼c┤¾╝ęę╗ŲėæšōųŪ─▄┴─╠ņÖCŲ„╚╦ąĪ³Sļu~ųvĄ├▓╗║├šłęŖšÅŻ¼╠ß墚ł▌p┼░~╬¹╬¹
Į±╠ņĄ─ųvū∙ų„ę¬Ęų×ķ╚²éĆ▓┐ĘųŻ¼Ęųäe╩ŪŻ║1. ╩▓├┤╩ŪąĪ³Sļu 2.ąĪ³SļuĄ─╗∙▒ŠįŁ└Ē 3.╚ń║╬ūįųŲąĪ³SļuĪŻ
Part 1 ╩▓├┤╩ŪąĪ³Sļu
║▄ČÓ╚╦šJūRąĪ³Sļu╩ŪÅ─╚╦╚╦ŠW(w©Żng)ķ_╩╝Ą─Ż¼ų╗ę¬@ąĪ³SļuŻ¼╦³Š═Ģ■┼▄│÷üĒĖ·─Ń┴─╠ņĪŻ▀@Š═╩Ūę╗éĆĄõą═Ą─╚╦╣żųŪ─▄Ą─┴─╠ņÖCŲ„╚╦ĪŻ
īŹļH╔ŽŻ¼╚╦╚╦ŠW(w©Żng)ąĪ³Sļu╩Ū╚A┐Ųę╗╬╗08╝ēĄ─═¼īWŻ¼═©▀^╚╦╚╦ŠW(w©Żng)Įė┐┌Ż¼š{(di©żo)ė├Ēnć°┴─╠ņÖCŲ„╚╦SimSimiĄ─APIŻ¼ūįäė╗žÅ═╠ß墚▀ĪŻ
ę▓Š═╩ŪŽ┬łDŻ║

SimSimiūŅįń’L├ęė┌ęŲäėŲĮ┼_ĪŻų┴ė┌╦³Ą─Š▀¾wįŁ└Ēęį╝░īŹ¼F(xi©żn)ĘĮĘ©╬ęéāīóį┌║¾ā╔▓┐ĘųĮķĮBĪŻę▓Š═╩ŪšfŻ¼╚╦╚╦ŠW(w©Żng)ąĪ³SļuĄ─įŁą═Ż¼Š═╩ŪųŪ─▄┴─╠ņÖCŲ„╚╦SimSimiĪŻ─Ū├┤╩▓├┤╩Ū┴─╠ņÖCŲ„╚╦─žŻ┐
║åå╬ĄžšfŻ¼Š═╩Ū╗∙ė┌╚╦╣żųŪ─▄įŁ└Ē(Artificial IntelligenceŻ¼ęįŽ┬║åĘQAI)Ż¼═©▀^ī”┴─╠ņ╬─▒Š▀MąąĘų╬÷║¾Įo│÷æ¬┤Ą─ę╗ŅÉ│╠ą“ĪŻ╩└Įń╔ŽūŅįńĄ─┴─╠ņÖCŲ„╚╦šQ╔·ė┌20╩└╝o80─Ļ┤·Ż¼▀@┐ŅÖCŲ„╚╦├¹×ķ“░óĀ¢žÉ╠ž”Ż¼ė├BASICšZčįŠÄīæČ°│╔ĪŻČ°ė╔ė┌ųą╬─ī”“į~”äØĘųĄ──Ż║²╝░Ųń┴xĘ▒ČÓĄ╚Ą╚įŁę“Ż¼ųą╬─┴─╠ņÖCŲ„╚╦░l(f©Ī)š╣Ą├ŽÓī”▌^┬²Ż¼─┐Ū░ėą┌A╦╝Ą─ąĪiŻ¼É█▓®Ą─ąĪAŻ¼“vėŹę▓ėąĪŻ
Part 2 ąĪ³SļuĄ─╗∙▒ŠįŁ└Ē
AI┴─╠ņÖCŲ„╚╦ąĪ³SļuĄ─╣żū„┐╔ęį▒╗Ęų│╔ā╔éĆ▓┐ĘųŻ║ė¢ŠÜ+Ųź┼õĪŻŻ©ŲõīŹ║▄ČÓAIĄ─¢|╬„Č╝┐╔ęį▒╗▀@├┤äØĘųŻ¼▒╚╚ń╚╦─śūRäeŻ¼šZę¶ūRäeĄ╚Ą╚Ż®
2.1 ė¢ŠÜ
SimsimiųąĄ─“Į╠īW”Ż¼Š═╩Ūė¢ŠÜĄ─▀^│╠Ż¼─┐Ą─į┌ė┌śŗ(g©░u)Į©╗“╩ŪžSĖ╗į~ÄņĪŻ
┴„│╠├Ķ╩÷╚ńŽ┬Ż║
S1Ż║ė├æ¶═©▀^Į╠īWĮń├µŽ“ŽĄĮy(t©»ng)╠ß│÷ę╗éĆįÆŅ}┼cŽÓæ¬æ¬┤Ż╗
S2Ż║ŽĄĮy(t©»ng)ī”įōįÆŅ}▀MąąĘųį~Ż¼┼ąöÓįōįÆŅ}į┌ŽĄĮy(t©»ng)ų¬ūRÄņųąæ¬┤µĘ┼Ą─╬╗ų├Ż╗
S3Ż║į┌ŽĄĮy(t©»ng)ų¬ūRÄņųą╠Ē╝ėįōįÆŅ}╝░ŽÓæ¬æ¬┤ĪŻ
┐╔ęį┐┤ĄĮŻ¼▀@└’╔µ╝░ĄĮā╔éĆå¢Ņ}Ż║Įo│÷ę╗éĆįÆŅ}Ż¼ŽĄĮy(t©»ng)╩Ū╚ń║╬Ęųį~Ą─Ż┐į~Äņę¬╚ń║╬įO(sh©©)ėŗ▓┼─▄ėų┐ņėų£╩Ąžæ¬┤Ż┐
2.1.1Ęųį~ĘĮĘ©
ėą╚╦šJ×ķ╬ęĮ╠ąĪ³Sļu“░ŻĘŲĀ¢ĶF╦■╔Ž45Č╚ĮŪč÷═¹ąŪ┐š”╗ž┤╩Ū“║Ū║Ū”Ż¼─ŪŽ┬┤╬╦³į┘┐┤ĄĮ“░ŻĘŲĀ¢ĶF╦■╔Ž45Č╚ĮŪč÷═¹ąŪ┐š”š¹ŠõįÆĄ─Ģr║“▓┼Ģ■ėąŽÓæ¬╗ž┤ĪŻĄ½īŹļH╔ŽŻ¼Ž┬┤╬ų╗ę¬╦³┐┤ĄĮ“░ŻĘŲĀ¢ĶF╦■”Š═Ģ■“║Ū║Ū”┴╦║├┬’ĪŻ
▀@╩Ūę“×ķ┴─╠ņÖCŲ„╚╦Ą─┤µā”▓ó▓╗ęįŠõūė×ķå╬╬╗Ż©─Ūśė╠½┘MĢr┘M┐šķgŻ®Ż¼Č°╩Ūęįį~ĪŻė┌╩ŪŻ¼Ęųį~Ż¼Äū║§│╔×ķ┴─╠ņÖCŲ„╚╦Ą─║╦ą─ĪŻ
ėó╬─Ęųį~║├šfŻ¼╚╦╝ęė├┐šĖ±╩▓├┤Ą─Š═ĖŃČ©┴╦Ż¼Ą½ųą╬─▓╗ę╗śėŻ¼ī”ė┌ę╗ŠõįÆŻ¼╚╦éā┐╔ęįė├ūį╝║Ą─šJūRģ^(q©▒)Ęųį~šZŻ¼Č°ÖCŲ„╚╦ę¬į§├┤ū÷Ż¼Š═╩Ūųą╬─Ęųį~╦ŃĘ©Ą─蹊┐ĘČ«Ā┴╦ĪŻ
ųą╬─Ęųį~╝╝ąg(sh©┤)ā░╚╗╩Ūę╗éĆųžę¬Ą─蹊┐ĘĮŽ“Ż¼ļ`ī┘ė┌ūį╚╗šZčį╠Ä└ĒĪŻ¼F(xi©żn)ėąĄ─Ęųį~╦ŃĘ©┐╔ęįĘų×ķ╚²┤¾ŅÉŻ║╗∙ė┌ūųĘ¹┤«Ųź┼õĄ─Ęųį~ĘĮĘ©Īó╗∙ė┌Įy(t©»ng)ėŗĄ─Ęųį~ĘĮĘ©║═╗∙ė┌└ĒĮŌĄ─Ęųį~ĘĮĘ©ĪŻ
ė├æ¶į┌┴─╠ņĢrĄ─ę╗éĆ’@ų°╠ž³c╩Ū╦∙╠ß│÷Ą─įÆŅ}ę╗░ŃČ╝╩Ū▒╚▌^Č╠ąĪĄ─Ż¼Č°▓╗╩ŪķLŲ¬┤¾šōŻ¼▓╗Š▀ėąČ╬┬õŲ¬š┬ĮY(ji©”)śŗ(g©░u)Ż¼Į^┤¾ČÓöĄ(sh©┤)Š═╩Ū╔┘öĄ(sh©┤)ÄūŠõįÆĪŻ╗∙ė┌Įy(t©»ng)ėŗĄ─Ęųį~ĘĮĘ©▀mė├ė┌ėąČ╬┬õĪóŲ¬š┬ĮY(ji©”)śŗ(g©░u)ęį╝░╔ŽŽ┬╬─ĻP(gu©Īn)ŽĄĄ─╬─Č╬ĪŻ╗∙ė┌└ĒĮŌĄ─Ęųį~ĘĮĘ©─┐Ū░▓ó▓╗│╔╩ņŻ¼ŪęĢrķgÅ═ļsČ╚Ė▀Ż¼╦┘Č╚┬²ĪŻė┌╩ŪŻ¼ų╗ėą╗∙ė┌ūųĘ¹┤«Ųź┼õĄ─Ęųį~╩Ū▒╚▌^▀m║ŽĄ─ĪŻ
╗∙ė┌ūųĘ¹┤«Ųź┼õĄ─Ęųį~ĘĮĘ©Ż¼ėųĮąū÷ÖCąĄĘųį~ĘĮĘ©ĪŻ░┤ššÆ▀├ĶĘĮŽ“Ą─▓╗═¼Ż¼ÖCąĄĘųį~Ę©┐╔ęįĘų×ķš²Ž“Ųź┼õ║═─µŽ“Ųź┼õĪŻŻ©e.g. ūųĘ¹┤«“▒▒Š®╚A¤¤įŲ”Ż¼š²Ž“Ųź┼õ×ķĪČ▒▒Š®Ż¼╚A¤¤įŲĪĘŻ¼─µŽ“Ųź┼õ×ķĪČ▒▒Ż¼Š®╚A¤¤įŲĪĘŻ®─µŽ“Ųź┼õĄ─ŪąĘųš²┤_┬╩ę¬Ė▀ė┌š²Ž“Ųź┼õĘ©Ż¼×ķ┴╦▒Ńė┌░l(f©Ī)¼F(xi©żn)Ųń┴xŪąĘųŻ¼ėąĢr║“?q©▒)óā╔š▀ĮY(ji©”)║ŽŲüĒą╬│╔ļpŽ“Ųź┼õĘ©ĪŻ░┤šš▓╗═¼ķLČ╚ā×(y©Łu)Ž╚Ųź┼õĄ─ŪķørŻ¼┐╔ęįĘų×ķūŅ┤¾Ż©ūŅķLŻ®Ųź┼õ║═ūŅąĪŻ©ūŅČ╠Ż®Ųź┼õŻ¼ę▓Š═╩ŪķLį~ā×(y©Łu)Ž╚║═Č╠į~ā×(y©Łu)Ž╚ĪŻ░┤ššŲź┼õ▓╗│╔╣”Ģrųžą┬Ūą╚ĪĄ─▓▀┬įŻ¼ÖCąĄĘųį~Ę©┐╔ęįĘų×ķį÷ūųĘ©║═£pūųĘ©ĪŻ
╗∙ė┌į~ĄõĄ─“ļpŽ“ūŅ┤¾Ųź┼õ”Ę©╩Ū─┐Ū░ųą╬─ą┼Žó╠Ä└ĒųąūŅ║åå╬ėąą¦Ą─ĘĮĘ©Ż¼ėą▀@śėĄ─Įy(t©»ng)ėŗŻ║ØhšZ╬─▒Šųą90Żźū¾ėęĄ─ŠõūėŻ¼Ųõ┼cļpŽ“ūŅ┤¾Ųź┼õĄ─ĮY(ji©”)╣¹ŽÓ╬Ū║ŽŻ¼Č°Ūę╩Ūš²┤_Ą─Ęųį~ĮY(ji©”)╣¹ĪŻ
«öš²ĪóĘ┤Ž“ūŅ┤¾Ųź┼õ╦ŃĘ©Ą├│÷üĒĄ─ŪąĘųĮY(ji©”)╣¹▓╗ę╗śėĢrŻ¼Š═▒žĒÜī”Ųõ▀MąąŲń┴x╠Ä└ĒŻ¼į┌┤╦▓╗į┘┘ś╩÷ĪŻ
2.1.2į~ÄņįO(sh©©)ėŗ
ė╔ė┌ųą╬─į~Ą─╠ž³cŻ║1.ųą╬─į~╩Ūę╗éĆķ_Ę┼╝»Ż¼į~öĄ(sh©┤)į┌į÷ķLŻ╗2.ęį▓╗═¼ūųķ_Ņ^Ą─į~Ą─öĄ(sh©┤)─┐ūā╗»║▄┤¾Ż¼ČÓĄ─▀_ĄĮöĄ(sh©┤)░┘éĆŻ¼╔┘Ą─ę▓ėą┐╔─▄ų╗ėąę╗éĆ╗“š▀ø]ėąŻ╗3.į~Ą─ķLČ╚ūā╗»ę▓║▄┤¾Ż¼ėąå╬ūųį~Ż¼ę▓ėąė╔┴∙ĪóŲ▀éĆūų│╔į~Ą─ĪŻ
▀@Š═ę¬Ū¾į┌įO(sh©©)ėŗį~ĄõĢrŻ¼│²┴╦┐╝æ]įLå¢ą¦┬╩═ŌŻ¼▀ĆĄ├│õĘų┐╝æ]┤µā”└¹ė├┬╩ĪŻ
šł┐┤▀@ĘNöĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ż¼Š═─▄║▄║├ĄžŲĮ║ŌĢrķg┼c┐šķgĪŻ
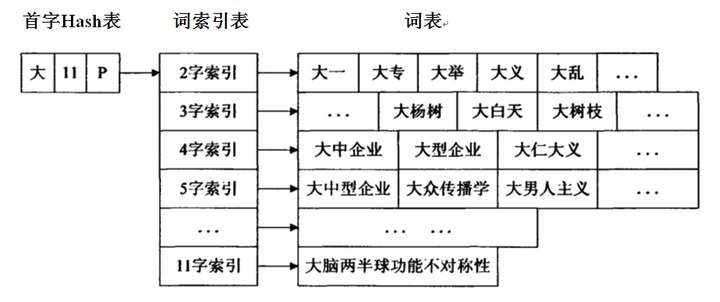
╩ūūųHash▒Ē═©▀^ę╗┤╬╣■ŽŻ▀\╦ŃŠ═┐╔ęįų▒ĮėČ©╬╗Øhūųį┌▒ĒųąĄ─╬╗ų├ĪŻę╗éĆå╬į¬░³└©╚²ĒŚā╚(n©©i)╚▌Ż║CŻ║┤µā”╩ūūųŻ╗Fś╦ųŠ╬╗Ż║┤µā”ęįC×ķ╩ūūųĄ─ūŅķLį~ŚlĄ─ķLČ╚Ż╗PŻ║ųĖŽ“į~▒Ē╦„ę²▒ĒĪŻ
ĮŌßīę╗Ž┬╣■ŽŻŻ║╔ó┴ą▒Ē Hash tableŻ¼ę▓Įą╣■ŽŻ▒ĒŻ¼ŅÖ├¹╦╝┴xŠ═╩Ū░čöĄ(sh©┤)ō■(j©┤)Č╝┤“╔ó┴╦Ż¼į┘░┤ę╗Č©ęÄ(gu©®)┬╔┤µŲüĒŻ¼╝ė┐ņįLå¢╦┘Č╚ĪŻ╩ŪĖ∙ō■(j©┤)ĻP(gu©Īn)µI┤aųĄKeyČ°ų▒Įė▀MąąįLå¢Ą─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)ĪŻ
┼eéĆ└§ūėŻ║╬ęŽļīó[0,100)ū÷│╔ę╗éĆ╣■ŽŻ▒ĒŻ¼▀x╚Ī“─Ż10”ū„×ķ╔ó┴ą║»öĄ(sh©┤)Ż¼ęįöĄ(sh©┤)ĮMū„×ķ┤µā”å╬į¬Ż¼ätĄ├ĄĮA[10][10]Ą─öĄ(sh©┤)ĮMŻ¼A[0]└’ę└┤╬┤µų°0,10,20…90Ż╗A[1]└’┤µų°1,11,21…91ĪŻę└┤╬ŅÉ═ŲĪŻ
¼F(xi©żn)į┌┼eę╗éĆė¢ŠÜąĪ³SļuĄ─└²ūėŻ║╬ęĮ╠ąĪ³Sļušf“┤¾░ū╠ņĄ─ū÷╩▓├┤├└ē¶░ĪŻ┐”╗ž┤╩Ū“┼Č╣■╣■╣■▓╗ė├─Ń╣▄”ĪŻ
S1Ż║æ¬ė├ļpŽ“ūŅ┤¾Ųź┼õ╦ŃĘ©Ęųį~Ż║ļpŽ“Ęųį~ĮY(ji©”)╣¹Ż¼š²Ž“ĪČ┤¾░ū╠ņŻ¼Ą─Ż¼ū÷╩▓├┤Ż¼├└ē¶Ż¼░ĪĪĘŻ╗Ę┤Ž“ĪČ┤¾░ū╠ņŻ¼Ą─Ż¼ū÷╩▓├┤Ż¼├└ē¶Ż¼░ĪĪĘĪŻš²Ž“Ę┤Ž“Č╝╩Ūę╗śėĄ─Ż¼╦∙ęį▓╗ąĶę¬╠Ä└ĒŲń┴xå¢Ņ}ĪŻķLį~ā×(y©Łu)Ž╚▀xō±Ż¼“┤¾░ū╠ņ”║═“ū÷╩▓├┤”ĪŻ
S2Ż║ęį“┤¾░ū╠ņ”┼e└²Ż¼╝┘įO(sh©©)hash║»öĄ(sh©┤)×ķfŻ©Ż®Ż¼▓óįO(sh©©)fŻ©┤¾░ū╠ņŻ®ųĖŽ“╩ūūųhash▒ĒĒŚ[┤¾Ż¼11Ż¼P]ĪŻė┌╩Ūė╔įō▒ĒĒŚųĖŽ““3ūų╦„ę²”Ż¼į┘ųĖŽ“?q©▒)”æ?ldquo;į~▒Ē”ĪŻ
S3Ż║īóĮY(ji©”)śŗ(g©░u)¾w<┤¾░ū╠ņŻ¼…>▓Õ╚ļĻĀ╬▓ĪŻ¾wųąėąę╗éĆAnsė“Ż¼ė“ųą─│ę╗ųĖßśųĖŽ““┼Č╣■╣■╣■▓╗ė├─Ń╣▄”ĪŻ
S4Ż║═Ļ│╔ė¢ŠÜĪŻ