
╬ęéāų¬Ą└Ż¼╔ńĮ╗łDūVėøõø╬ęéā?c©©)┌╔ńĮ╗├Į¾w╔ŽĄ─ĘNĘNĻP(gu©Īn)┬ō(li©ón)ĪŻÅ─╦č╦„ĮY(ji©”)╣¹ĄĮā×(y©Łu)╗▌╚»Ż¼╗∙ė┌╔ńĮ╗łDūVĄ─Ę■äš(w©┤)ęčĮø(j©®ng)īęęŖ(ji©żn)▓╗§rĪŻį┌▀@═¼Ģr(sh©¬)Ż¼ę╗éĆ(g©©)Č©╬╗Ė³╝ėŠ½£╩(zh©│n)Ą─éĆ(g©©)╚╦╗»ŠW(w©Żng)Įj(lu©░)š²į┌┬²┬²ß╚Ų——╗∙ė┌ė├æ¶éĆ(g©©)╚╦Ž▓║├Ą─┼d╚żłDūVŠW(w©Żng)Įj(lu©░)Ę■äš(w©┤)ĪŻ¼F(xi©żn)į┌ęčĮø(j©®ng)ėąę╗ą®Ęų╔óĄ─┼d╚żłDūVŻ¼▒╚╚ń╣╚ĖĶĄ─éĆ(g©©)╚╦╗»╦č╦„Ż¼╗“š▀AmazonĄ─═Ų╦]ę²ŪµĪŻėąą®╣½╦ŠŽŻ═¹▀@ĘNĘ■äš(w©┤)┐╔ęįĖ▓╔w╬ęéā?n©©i)½▓┐Ą─ŠW(w©Żng)Įj(lu©░)╔·╗ŅŻ¼Č°▀@Š═ęŌ╬Čų°Ż¼╬ęéāĄ─╦∙ĄĮų«╠Ä╦∙ęŖ(ji©żn)ų«╬’Ż¼Č╝╩Ū╬ęéāĄ─ą─ų«╦∙Ž“ĪŻęŌ╬Čų°╬ęéā▓╗į┘ąĶę¬į┌ą┬┬äŠW(w©Żng)šŠ╔Ž╦č╦„Ž▓ÜgĄ─╣╩╩┬Ż¼╗“į┌┘Å(g©░u)╬’ŠW(w©Żng)šŠ╔Ž▓ķšęąĶꬥ─╔╠ŲĘ——ę“?y©żn)ķę╗Ą®ĄŪĻæ▀@ą®ŠW(w©Żng)šŠŻ¼ŠW(w©Żng)šŠŽĄĮy(t©»ng)Š═Ģ■(hu©¼)ūįäė(d©░ng)ūR(sh©¬)äe╬ęéā╩Ūšl(shu©¬)Ż¼╬ęéāŽ▓Üg╩▓├┤Ż¼▓ó│╩¼F(xi©żn)╬ęéā╦∙ąĶĄ─ā╚(n©©i)╚▌ą┼ŽóĪŻ
▓╗╣▄▀@ĘNśŗ(g©░u)ŽļĦĮo─ŃĄ─╩Ū¾@Ž▓▀Ć╩Ū┐ų╗┼Ż¼╬ęéāČ╝æ¬(y©®ng)įō┐┤┐┤▀@ĘN═Ļ╚½éĆ(g©©)╚╦╗»Ą─ŠW(w©Żng)Įj(lu©░)Š▀¾w╩Ūį§śė▀\(y©┤n)ū„Ą─ĪŻ
░l(f©Ī)¼F(xi©żn)─ŃŽ▓Üg╩▓├┤
╩┬īŹ(sh©¬)╔ŽŻ¼Twitter║═FacebookĄ╚╔ńĮ╗ŠW(w©Żng)šŠį┌┤_Č©╚╦éāĄ─īŹ(sh©¬)ļH┼d╚żĢr(sh©¬)Ż¼╗“įS▓óø](m©”i)ėąŽ±į┌Ųõ╦¹ŠW(w©Żng)šŠ╔ŽĄ─³c(di©Żn)ō¶╗“š▀įu(p©¬ng)šō─Ū├┤ėąą¦ĪŻ║▄ČÓ╚╦į┌Twitter╔ŽĘųŽĒą┼Žó╩Ūę“?y©żn)ķ┬ÜśI(y©©)ąĶ꬯¼ė├æ¶║▄ČÓĢr(sh©¬)║“į┌Facebook╔ŽĘųŽĒĄ─ą┼Žóę▓āHŽ▐ė┌×ķĮ╗ļH╚”Ę■äš(w©┤)ĪŻ▓╗╣▄╩Ūį┌──ĘNŪķørŽ┬Ż¼“║▄ČÓĢr(sh©¬)║“Ż¼╚╦éāČ╝ų╗╩Ūį┌ū„ąŃŻ¼ęįŲ┌Įo╚╦┴¶Ž┬║├ėĪŽ¾ĪŻ▀@Š═ī¦(d©Żo)ų┬┴╦ė├æ¶öĄ(sh©┤)ō■(j©┤)Ą─▓╗═Ļš¹ĪŻ”
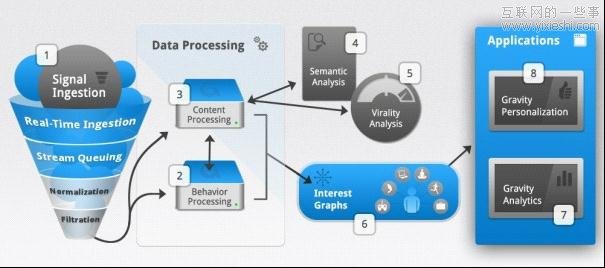
─Ū┼d╚żłDūV╩Ūį§śė╣żū„Ą──ž?äō(chu©żng)śI(y©©)╣½╦ŠGravityš²╩Ū╗∙ė┌▀@ę╗Ę■äš(w©┤)Ą─ę╗╝ę╣½╦ŠŻ¼ŲõCTO Jim BenedettoŽ“╬ęéāĮķĮB┴╦ŠW(w©Żng)šŠĄ─╣żū„įŁ└ĒĪŻGravity═¼Ģr(sh©¬)×ķČÓ╝ęŠW(w©Żng)šŠĘ■äš(w©┤)Ż¼╦³Ģ■(hu©¼)Ė·█Öė├æ¶į┌Ųõ╦∙ėąĘ■äš(w©┤)ŠW(w©Żng)šŠĄ─ąą×ķŻ¼▀@śėė├æ¶į┌ĄŪĻæ╚╬ęŌŠW(w©Żng)šŠĢr(sh©¬)Ż¼Č╝─▄ūįäė(d©░ng)½@Ą├╠ž╔½ā╚(n©©i)╚▌ĪŻ─Ń┐╔ęį³c(di©Żn)ō¶▀@└’┐┤ĄĮŠW(w©Żng)šŠśŗ(g©░u)Į©ę╗Ę∙łDūVĄ─Š▀¾w┴„│╠ĪŻ
Å─╝╝ąg(sh©┤)īė├µüĒ(l©ói)šf(shu©Ł)Ż¼Gravity╩Ū═©▀^(gu©░)ę╗éĆ(g©©)╗∙ė┌Freebase ║═ DBpediaĄ╚ČÓéĆ(g©©)öĄ(sh©┤)ō■(j©┤)╝»Ą─┤¾ą═öĄ(sh©┤)ō■(j©┤)ę²ŪµŻ¼┤_Č©ė├æ¶į┌³c(di©Żn)ō¶─│Ų¬╬─š┬╗“░l(f©Ī)▒Ē─│éĆ(g©©)įu(p©¬ng)šōĢr(sh©¬)Ą─īŹ(sh©¬)ļH┼d╚ż³c(di©Żn)ĪŻ┼eéĆ(g©©)└²ūėŻ¼ę╗éĆ(g©©)ė├æ¶╚ń╣¹░l(f©Ī)▒ĒVanessa Laine(║■╚╦ĻĀ(du©¼)NBAŪ“åT┐Ų▒╚Ą─Ū░Ų▐)Ą─TweetŻ¼─Ū╦¹æ¬(y©®ng)įō╩Ūī”(du©¼)╗@Ū“Ė³Ėą┼d╚żŻ¼Č°▓╗╩ŪLaineĄ─│÷╔·╚šŲ┌╗“š▀Ųõ╦¹┤_ŪąĄ½▓╗ŽÓĻP(gu©Īn)Ą─ą┼ŽóĪŻ
ļS╔ĒöyĦ“éĆ(g©©)╚╦ś╦(bi©Īo)║×”
ėąę╗╠ņŻ¼╚╦éā▓╗╣▄╩Ū×gė[╩▓├┤ŠW(w©Żng)Ēō(y©©)Ż¼Č╝┐╔ęį╗∙ė┌ūį╝║Ą─┼d╚żĪŻ
▀@┤_īŹ(sh©¬)╩Ūę╗éĆ(g©©)ę²╚╦ūó─┐Ą─įĖŠ░Ż║╬ęéāĄ─┼d╚żłDūVĢ■(hu©¼)ė░Ēæ╬ęéā?c©©)┌╚╬ęŌę╗éĆ(g©©)ŠW(w©Żng)šŠ╔Ž┐┤ĄĮĄ─ā╚(n©©i)╚▌ĪŻ╚ń╣¹─ŃŽ▓Üg╗¼č®Ż¼─Ū─Ń┐╔─▄Š═Ģ■(hu©¼)į┌ļŖūė╔╠äš(w©┤)ŠW(w©Żng)šŠ╔Ž┐┤ĄĮ╗¼č®įO(sh©©)éõĄ─ŽÓĻP(gu©Īn)Į╗ęūą┼ŽóĪŻČ°ŪęŻ¼║▄ėą┐╔─▄─ŃČ╝▓╗ė├ĄŪĻæŠ═─▄┐┤ĄĮ▀@ą®ą┼ŽóŻ¼ę“?y©żn)ķ▀@ą®ŠW(w©Żng)šŠĢ■(hu©¼)ŠC║Ž┐╝┴┐─Ńį┌š¹éĆ(g©©)ŠW(w©Żng)Įj(lu©░)Ą─ąą×ķĪŻ
▒M╣▄¼F(xi©żn)į┌ęčĮø(j©®ng)ėąę╗ą®Ęų╔óĄ─┼d╚żłDūVŻ¼Ą½šµš²Ą─ļy³c(di©Żn)╩ŪŻ¼╚ń║╬īó▀@ą®Ęų╔óĄ─Ż¼┴Ń╦ķĄ─┼d╚żłDūVš¹║Ž│╔ę╗éĆ(g©©)Įy(t©»ng)Ą─ĻP(gu©Īn)ė┌╬ęéā╩Ūšl(shu©¬)Ż¼Ž▓Üg╩▓├┤Ą─éĆ(g©©)╚╦ś╦(bi©Īo)║×ĪŻėą┐╔─▄Ż¼ųT╚ńOAuth(į╩įS╗∙ė┌APIĄ─öĄ(sh©┤)ō■(j©┤)┐╔ęįį┌▓╗═¼Ę■äš(w©┤)ķg╣▓ŽĒ)▀@śėĄ─ĘĮĘ©Ģ■(hu©¼)Ųū„ė├ĪŻ▀@śė─Ńį┌╔ŽŠW(w©Żng)Ą─Ģr(sh©¬)║“ų╗ꬥŪõøę╗┤╬Ż¼─ŃĄ─┼d╚żłDūVŠ═╠Äė┌“ī(q©▒)äė(d©░ng)ĀŅæB(t©żi)Ż¼▓óūīš¹éĆ(g©©)ŠW(w©Żng)Įj(lu©░)╗∙ė┌─ŃĄ─ąĶŪ¾×ķ─ŃĘ■äš(w©┤)ĪŻ
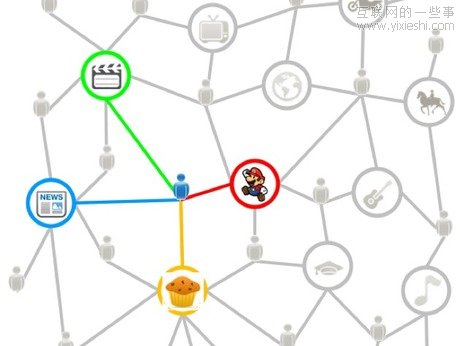
šµš²×ķ─Ń╦∙ė├
«ö(d©Īng)╚╗Ż¼▒M╣▄║▄ČÓ╚╦Ģ■(hu©¼)Ž▓Üg▀@ĘNéĆ(g©©)╚╦╗»Ą─╔ŽŠW(w©Żng)¾w“×(y©żn)Ż¼ę▓Ģ■(hu©¼)ėą╚╦ō·(d©Īn)ą─ļ[╦Įå¢(w©©n)Ņ}ĪŻČ°ŪęŻ¼ėą╚╦Ģ■(hu©¼)ŽŻ═¹ūį╝║┐╔ęįļSęŌ╔ŽŠW(w©Żng)Ż¼Č°▓╗╩Ūė╔ŠW(w©Żng)šŠüĒ(l©ói)ŅA(y©┤)£y(c©©)╦¹éāŽ▓Üg╩▓├┤ĪŻ╗∙ė┌▀@éĆ(g©©)įŁę“Ż¼▀@ĘNéĆ(g©©)╚╦╗»Ą─ŠW(w©Żng)Įj(lu©░)▒žĒÜ╩Ū┐╔▀xĘ■äš(w©┤)Ż¼Č°▓╗╩Ū▒ž▀xĘ■äš(w©┤)ĪŻ
ļ[╦Įå¢(w©©n)Ņ}╩Ūę╗éĆ(g©©)╝¼╩ųĄ─å¢(w©©n)Ņ}ĪŻ╦∙ęįŻ¼ė├æ¶æ¬(y©®ng)įōėąÖÓ(qu©ón)øQČ©╦¹éāĄ───ą®╔ŽŠW(w©Żng)ėøõøĢ■(hu©¼)│╔×ķ╦¹éāéĆ(g©©)╚╦ś╦(bi©Īo)║ץ─ę╗▓┐ĘųĪŻ┼eéĆ(g©©)└²ūėŻ¼┤¾▓┐ĘųŽ▓Üg╔½ŪķęĢŅlĄ─ė├æ¶Č╝▓╗ŽŻ═¹╦¹éāĄ─▀@ę╗Ž▓║├Ż¼Ģ■(hu©¼)ė░Ēæ╦¹éā▒╗═Ų╦]Ą─ą┬┬äā╚(n©©i)╚▌Ż¼╗“š▀«ö(d©Īng)╦¹Ė·┼«┼¾ėčį┌ė^┐┤─│éĆ(g©©)▒╚┘ÉĢr(sh©¬)Ż¼ŠW(w©Żng)šŠ═╗╚╗═Ų╦]╔½ŪķęĢŅlĪŻ╦∙ęįŻ¼ŠW(w©Żng)šŠ▒žĒÜįO(sh©©)Č©ŽÓæ¬(y©®ng)Ą─╩┌ÖÓ(qu©ón)░┤ŌoŻ¼ęį╝░“šł(q©½ng)╬ūĘ█Ö”░┤ŌoŻ¼ęį┤_▒Ż▀@ĘNéĆ(g©©)╚╦╗»Ą─ŠW(w©Żng)Įj(lu©░)▓╗Ģ■(hu©¼)│╔×ķė├æ¶Ą─ĮO─_╩»ĪŻ
▒M╣▄╬ęéāėą┐╔─▄Ģ■(hu©¼)║▄Ž▓Üg▀@ĘNéĆ(g©©)╚╦╗»Ą─ŠW(w©Żng)Įj(lu©░)Ż¼Ą½╩ŪĘ▓╩┬Č╝æ¬(y©®ng)įōėąę╗éĆ(g©©)Č╚ĪŻ╦∙ų^Ą─éĆ(g©©)╚╦╗»ŠW(w©Żng)Įj(lu©░)Ę■äš(w©┤)Ż¼│²┴╦▒ŻūCŠW(w©Żng)Įj(lu©░)ą┼Žó│╩¼F(xi©żn)Ą─éĆ(g©©)╚╦╗»ęį═ŌŻ¼▀Ćæ¬(y©®ng)įō▒ŻūCĘ■äš(w©┤)▒Š╔ĒĄ─╚╦ąį╗»Ż¼šµš²×ķė├æ¶╦∙ė├ĪŻ